云函数与传统后端:何时选择无服务器架构
对无服务器函数和传统后端进行真实世界的比较——涵盖成本、延迟、开发者体验,以及每种方法何时更具优势。
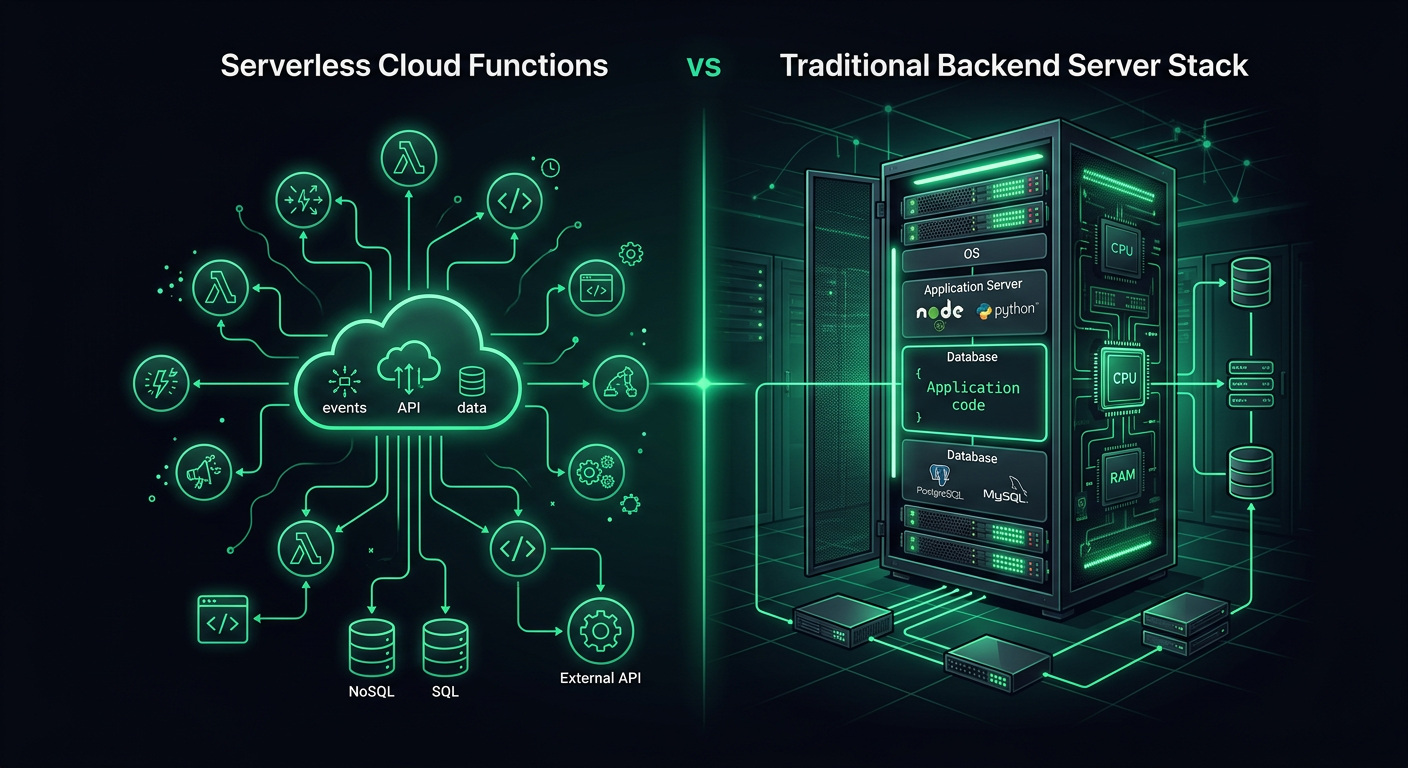
我启动的每一个全新项目都面临着同样的选择:是搭建一个传统服务器,还是编写云函数?在两类生产系统都交付之后——Firebase Functions 用于事件驱动型工作流,AWS Lambda 用于 API 端点,以及 Express/Fastify 服务器用于介于两者之间的所有场景——我对每种方法何时真正胜出有了相当细致的看法。答案不出所料是“视情况而定”,但具体取决于什么值得详细探讨。
定义两种方法
在比较之前,让我精确地定义每种方法的含义。
传统后端指的是一个长时间运行的服务器进程——一个 Node.js Express 应用、一个 Python FastAPI 服务器、一个 Go HTTP 服务器——部署在虚拟机 (VM)、容器或托管计算平台上。该进程启动后会持续运行,并处理到达的请求。部署目标包括 EC2、Cloud Run、ECS、Railway、Fly.io 或裸机 VPS。
云函数(无服务器函数)是响应事件而执行的独立函数处理程序。平台完全管理计算基础设施。您的代码运行,返回响应,并且执行环境可能会或可能不会为下一次调用而持久存在。提供商包括 AWS Lambda、Google Cloud Functions、Firebase Functions、Azure Functions 和 Cloudflare Workers。
这种区别不在于语言或框架,而在于执行模型。传统后端拥有其进程生命周期。云函数则没有。
冷启动的现实
冷启动是无服务器架构最受讨论的限制,而 2026 年的现实比讨论所暗示的更为细致。
冷启动时实际发生了什么
当云函数最近未被调用(或并发调用超出可用热实例)时,平台必须:
- 预置一个新的执行环境(微虚拟机或容器)
- 下载并解压您的部署包
- 初始化运行时(Node.js、Python 等)
- 执行您的初始化代码(模块导入、SDK 设置、数据库连接)
- 执行实际的函数处理程序
步骤 1-3 是平台开销。步骤 4 是您的代码选择至关重要的地方。
实践中的冷启动数据
以下是我在实际项目中,针对不同平台和配置测量的冷启动时间:
| Platform | Runtime | Bundle Size | Cold Start |
|---|---|---|---|
| AWS Lambda | Node.js 20 | 5 MB | 250-400ms |
| AWS Lambda | Node.js 20 | 50 MB | 800-1200ms |
| AWS Lambda | Python 3.12 | 10 MB | 400-600ms |
| Firebase Functions v2 | Node.js 20 | 15 MB | 600-1000ms |
| Cloudflare Workers | JavaScript | 1 MB | 0-5ms |
| Google Cloud Functions v2 | Node.js 20 | 10 MB | 300-500ms |
Cloudflare Workers 是一个例外,因为它们使用 V8 隔离区而不是容器,这完全消除了容器启动的开销。其权衡是运行时环境更为受限。
缓解冷启动
有几种策略确实有所帮助:
预置并发 (Lambda): 始终保持 N 个实例处于“热”状态。预置容量每 GB-秒的成本为 $0.0000041667。对于一个 256MB 的函数,每个热实例每月大约 $3.20。对于延迟敏感的端点来说是值得的。
最小实例数 (Cloud Run, Firebase Functions v2): 概念相同,命名不同。Cloud Run 对空闲实例按折扣费率收费。
减小打包大小: 这是投入产出比最高的策略。通过 Tree-shaking、排除开发依赖项以及使用更轻量的 SDK 客户端,可以显著减少初始化时间。
// Bad: imports the entire AWS SDK (adds 40MB+ to bundle)
import AWS from 'aws-sdk';
// Good: imports only the S3 client (adds ~3MB)
import { S3Client, GetObjectCommand } from '@aws-sdk/client-s3';
延迟初始化: 不要在模块作用域内建立数据库连接或加载重型资源。在首次调用时初始化它们,并在后续热调用中重用。
import { Pool } from 'pg';
let pool: Pool | null = null;
function getPool(): Pool {
if (!pool) {
pool = new Pool({
connectionString: process.env.DATABASE_URL,
max: 1, // Single connection per Lambda instance
});
}
return pool;
}
export async function handler(event: APIGatewayEvent) {
const db = getPool();
const result = await db.query('SELECT * FROM users WHERE id = $1', [event.pathParameters?.id]);
return { statusCode: 200, body: JSON.stringify(result.rows[0]) };
}
不同规模下的成本比较
成本是讨论变得有趣的地方,因为随着流量的增长,经济效益会发生逆转。
低流量(每天 1,000 - 50,000 次请求)
在这个规模下,无服务器架构几乎总是更便宜。许多初创公司和个人项目都属于这一类。
每天 30,000 次请求、平均持续时间 200 毫秒、256MB 内存的 Lambda 成本:
- 请求费用:每月 90 万次请求 x $0.20/百万次 = $0.18
- 计算费用:90 万 x 0.2 秒 x 0.25GB x $0.0000166667 = $0.75
- 总计:每月约 $1
等效传统服务器(AWS 上的 t4g.small):
- 按需:每月 $12.26
- 1 年期 Savings Plan:每月约 $8
在低流量下,您正在为一个 95% 时间处于空闲状态的常驻服务器付费。
中等流量(每天 100,000 - 1,000,000 次请求)
这是比较接近的交叉区域。
每天 500,000 次请求、平均 200 毫秒、256MB 的 Lambda 成本:
- 请求费用:每月 1500 万次请求 x $0.20/百万次 = $3.00
- 计算费用:1500 万 x 0.2 秒 x 0.25GB x $0.0000166667 = $12.50
- 总计:每月约 $15.50
t4g.medium (2 vCPU, 4GB RAM):
- 按需:每月 $24.53
- 1 年期 Savings Plan:每月约 $16
成本相当,但传统服务器处理此流量时有显著的余量。如果您的流量稳定,服务器会稍微便宜一些。如果您的流量是突发性的(工作日流量大、事件驱动的爆发),Lambda 的按调用计费意味着您无需为安静时段付费。
高流量(每天 5,000,000+ 次请求)
在这个规模下,对于持续的工作负载,无服务器架构几乎总是更昂贵。
每天 5,000,000 次请求、平均 200 毫秒、512MB 的 Lambda 成本:
- 请求费用:每月 1.5 亿次请求 x $0.20/百万次 = $30
- 计算费用:1.5 亿 x 0.2 秒 x 0.5GB x $0.0000166667 = $250
- 总计:每月约 $280
c6g.large (2 vCPU, 4GB RAM) 搭配自动扩缩组:
- 2 个实例(带 Savings Plan):每月约 $60
- 带负载均衡器:每月约 $16
- 总计:每月约 $76
在这个规模下,传统方法便宜 3.7 倍,并且随着流量的增加,差距会进一步扩大。
需要考虑的隐藏成本
Lambda 的计费并非全部。如果使用,还需要加上 API Gateway(每百万次请求 $1-3.50)、CloudWatch Logs(每 GB 摄入 $0.50)和 X-Ray 追踪。在传统方面,需要加上负载均衡器成本、监控以及管理实例和部署的运维时间。
开发者体验差异
无服务器开发体验
优点:
- 无需管理基础设施(无需打补丁、无需配置扩缩)
- 按函数部署意味着更小的影响范围
- 使用模拟器进行本地开发(Firebase Emulator Suite、SAM CLI、Serverless Framework offline)
- 通过平台的日志和追踪实现内置可观测性
痛点:
- 本地开发永远无法完美匹配生产行为
- 调试分布式函数间调用比调试单体应用更困难
- 部署大小限制(Lambda:解压后 250MB)限制了依赖项的选择
- IAM 和权限配置冗长且容易出错
- 冷启动使得针对已部署函数进行测试时的开发迭代周期变慢
传统后端开发体验
优点:
- 本地开发环境即生产环境(相同的进程、相同的状态)
- 调试直接明了——附加调试器、设置断点、单步执行
- 没有部署大小限制
- 中间件模式、请求生命周期钩子和全局错误处理是自然而然的
- WebSocket 支持、长时间运行的进程和后台作业无需额外服务即可工作
痛点:
- 您拥有基础设施生命周期(更新、扩缩、健康检查)
- 部署需要编排(滚动更新、健康检查宽限期)
- 扩缩需要配置(自动扩缩组、容器编排)
- 监控和日志记录需要明确设置
框架差距正在缩小
像 SST (Serverless Stack) 和 Architect 这样的框架极大地改善了无服务器开发体验。特别是 SST 提供了一种“Live Lambda”开发模式,您的本地运行代码可以实时处理 Lambda 调用,完全消除了部署-测试循环。
在传统方面,Railway、Fly.io 和 Render 等平台已将部署简化为 git push。运行传统后端的运维负担已显著减轻。
无服务器架构何时胜出
事件驱动型工作负载
如果您的代码响应事件运行——文件上传、数据库更改、队列消息、计划任务——那么无服务器架构是自然的选择。您无需维护轮询循环或监听进程。平台会在需要时精确触发您的代码。
// Firebase Functions: triggered on Firestore document creation
import { onDocumentCreated } from 'firebase-functions/v2/firestore';
export const onOrderCreated = onDocumentCreated('orders/{orderId}', async (event) => {
const order = event.data?.data();
if (!order) return;
// Send confirmation email
await sendEmail(order.customerEmail, {
template: 'order-confirmation',
data: { orderId: event.params.orderId, items: order.items },
});
// Update inventory
await updateInventory(order.items);
// Notify restaurant
await sendPushNotification(order.restaurantId, {
title: 'New Order',
body: `Order #${event.params.orderId} received`,
});
});
零星或不可预测的流量
一个内部工具,周一早上收到 50 个请求,而一周的其余时间只有 2 个请求。一个处理第三方 API 事件的 webhook 接收器。一个每天运行 30 秒的计划报告生成器。这些工作负载在无服务器架构上成本接近于零,而在常驻基础设施上则会浪费金钱。
低到中等流量的 API 端点
对于一个每天处理数千次请求的初创公司 MVP API,无服务器架构提供了一个功能齐全的后端,运维开销极小,成本接近于零。您可以完全专注于业务逻辑。
并行数据处理
需要处理 10,000 张图片、转码 500 个视频,或对大型数据集运行分析?可以扇出到数千个并发的 Lambda 调用,并行处理,并且只为使用的计算时间付费。使用传统服务器实现相同的并行性需要预置(并支付)峰值容量。
传统后端何时胜出
持久连接
WebSocket 连接、Server-Sent Events、gRPC 流和长轮询都需要客户端和服务器之间建立持久连接。Lambda 函数有 15 分钟的执行限制,并且不适用于长时间连接。
您可以使用 API Gateway WebSocket API 或 AWS IoT Core 来解决这个问题,但其复杂性和成本通常会超过在 Cloud Run 或容器平台上运行的简单 WebSocket 服务器。
复杂请求管道
当一个请求经过身份验证、速率限制、输入验证、业务逻辑、数据库操作、缓存更新、事件发送和响应格式化时——Express/Fastify/Koa 的中间件管道模式在人体工程学上优于云函数的扁平处理程序模式。
// Traditional: clean middleware pipeline
app.use(cors());
app.use(helmet());
app.use(rateLimiter);
app.use(authenticate);
app.use('/api/v1', apiRouter);
app.use(errorHandler);
在 Lambda 中复制这一点需要使用像 Middy 这样的框架(这会增加重量和复杂性)或在多个函数中重复设置代码。
有状态操作
如果您的应用程序维护内存状态——缓存、连接池、速率限制计数器、会话数据——传统服务器可以自然地处理这些。Lambda 函数可以在热调用中重用状态,但您不能依赖它。任何必须持久化的状态都需要外部服务(Redis、DynamoDB),这会增加延迟和成本。
严格的延迟要求
对于每一毫秒都至关重要的 API——实时竞价、游戏服务器、金融交易——冷启动带来的不可预测的延迟是不可接受的,即使有预置并发也一样。一个经过良好调优的、带有连接池和热缓存的服务器进程可以提供无服务器架构无法保证的稳定低于 10 毫秒的响应时间。
混合方法
实际上,我构建的大多数生产系统最终都采用混合模式。核心 API 运行在传统后端(Cloud Run 或容器平台)上,而辅助工作负载则运行在云函数上。
实际的混合架构
Client
│
├─→ API Gateway / Load Balancer
│ └─→ Cloud Run (main API)
│ ├─→ PostgreSQL (Cloud SQL)
│ ├─→ Redis (Memorystore)
│ └─→ Pub/Sub (event bus)
│
└─→ Cloud Functions (event handlers)
├─→ Image processing (on upload)
├─→ Email sending (on order creation)
├─→ Analytics aggregation (scheduled)
└─→ Webhook processing (HTTP trigger)
主 API 处理带有持久数据库连接、内存缓存和一致延迟的同步请求-响应流量。云函数处理异步、事件驱动的工作负载,在这种情况下冷启动无关紧要,因为用户无需等待响应。
迁移策略:从传统到无服务器
如果您有一个现有的传统后端并希望选择性地采用无服务器架构:
- 识别事件驱动型操作,目前作为后台作业、cron 任务或队列消费者运行。这些是最容易迁移的。
- 提取不与其他端点共享状态的独立端点。健康检查端点、webhook 接收器和实用工具 API 都是不错的选择。
- 保持核心 API 传统,除非您有充分的理由对其进行分解。管理 50 个 Lambda 函数的运维开销通常超过管理一个容器。
- 使用事件总线(Pub/Sub、EventBridge、SQS)作为传统 API 和无服务器函数之间的集成层。API 发布事件;函数订阅并作出反应。
迁移策略:从无服务器到传统
当无服务器 API 超越其架构时,有时需要反向迁移:
- 不要一次性重写所有内容。 从将流量最高的函数整合到一个 API 服务器开始。
- 保持事件驱动型函数为函数。 只迁移请求-响应处理程序。
- 使用相同的 API 路由。 将您的 API Gateway/负载均衡器指向新服务器以处理已迁移的路由,并继续将其余路由指向 Lambda。
- 首先迁移数据库连接。 最大的性能提升是将每次调用建立连接改为持久连接池。
平台特定说明
Firebase Functions (v2)
Firebase Functions v2 底层运行在 Cloud Run 上,这使其相对于 v1 具有显著优势:可配置的并发性(每个实例处理多个请求)、最小实例数、更长的超时时间(最长 60 分钟)和更大的内存分配。如果您正在使用 Firebase v1 函数,升级到 v2 值得付出迁移努力。
Firebase Emulator Suite 提供了无服务器领域最佳的本地开发体验。它在一个本地环境中模拟 Firestore、Auth、Storage 和 Functions,并支持代码更改时的热重载。
AWS Lambda
Lambda 拥有最深入的集成生态系统——几乎所有 AWS 服务的触发器、用于共享代码的层以及用于 Java 工作负载的 SnapStart。函数 URL 功能消除了简单用例对 API Gateway 的需求,每百万次请求可节省 $3.50。
Lambda@Edge 和 CloudFront Functions 在 CDN 层面进行请求/响应操作非常强大,但其开发和调试体验明显不如标准 Lambda。
Cloud Run
Cloud Run 模糊了无服务器和传统之间的界限。它运行容器(任何语言、任何框架),可扩缩到零,并支持并发(每个实例处理多个请求)。它在计费模型上是无服务器的,但在执行模型上是传统的。对于希望获得无服务器经济效益而无需将代码重写为函数处理程序的团队来说,Cloud Run 通常是正确的选择。
做出决策
以下是我使用的决策框架:
- 工作负载是事件驱动和异步的吗? 无服务器。
- 流量低且不可预测吗? 无服务器。
- 您需要持久连接或内存状态吗? 传统。
- 一致的低延迟至关重要吗? 传统。
- 团队规模小且不愿进行运维吗? 无服务器(或 Cloud Run)。
- 流量高且稳定吗? 传统(更便宜)。
- 是上述情况的混合吗? 混合。
最糟糕的决定是将其视为非此即彼的选择。为每个工作负载使用正确的工具,通过明确定义的接口将它们连接起来,您将获得两者的好处,而无需完全致力于其中任何一种。