Облачные функции против традиционного бэкенда: когда бессерверная архитектура имеет смысл
Сравнение бессерверных функций и традиционных бэкендов в реальных условиях — охватывающее стоимость, задержку, опыт разработчика и случаи, когда каждый подход выигрывает.
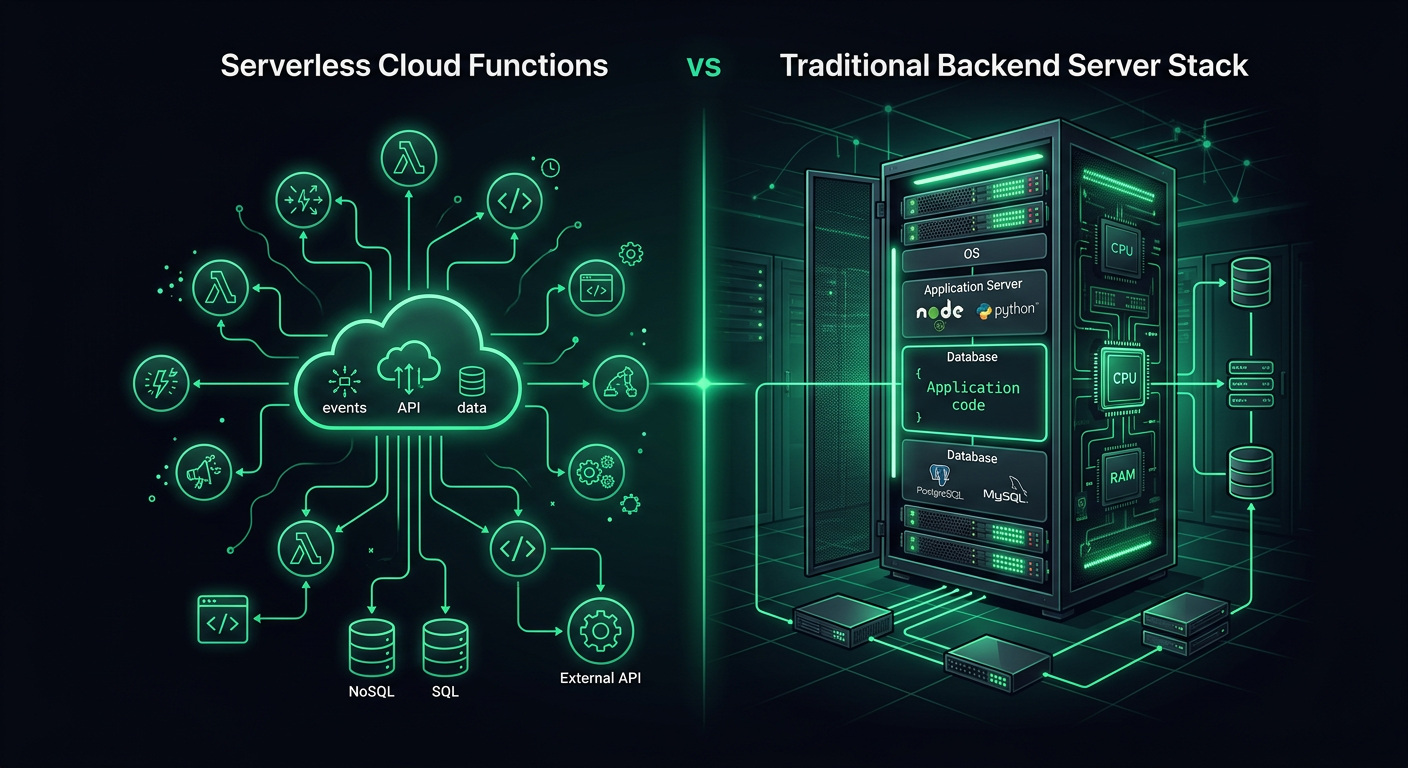
Каждый новый проект, который я начинаю, ставит передо мной один и тот же вопрос: развернуть традиционный сервер или написать облачные функции? После запуска производственных систем с использованием обоих подходов — Firebase Functions для событийных рабочих процессов, AWS Lambda для конечных точек API и серверов Express/Fastify для всего остального — у меня сложилось довольно тонкое мнение о том, когда каждый подход действительно выигрывает. Ответ, предсказуемо, "зависит от обстоятельств", но стоит подробно изучить, от чего именно он зависит.
Определение двух подходов
Прежде чем сравнивать, позвольте мне уточнить, что я подразумеваю под каждым из них.
Традиционный бэкенд относится к долгоживущему серверному процессу — приложению Node.js Express, серверу Python FastAPI, HTTP-серверу Go — развернутому на виртуальной машине, в контейнере или на управляемой вычислительной платформе. Процесс запускается, остается запущенным и обрабатывает запросы по мере их поступления. Цели развертывания включают EC2, Cloud Run, ECS, Railway, Fly.io или обычный VPS.
Облачные функции (бессерверные функции) — это отдельные обработчики функций, которые выполняются в ответ на события. Платформа полностью управляет вычислительной инфраструктурой. Ваш код выполняется, возвращает ответ, и среда выполнения может сохраняться или не сохраняться для следующего вызова. Провайдеры включают AWS Lambda, Google Cloud Functions, Firebase Functions, Azure Functions и Cloudflare Workers.
Различие не в языке или фреймворке — оно в модели выполнения. Традиционный бэкенд управляет жизненным циклом своего процесса. Облачная функция — нет.
Реальность "холодного старта"
Холодные старты — это наиболее обсуждаемое ограничение бессерверной архитектуры, и реальность в 2026 году более нюансирована, чем предполагает дискурс.
Что на самом деле происходит во время холодного старта
Когда облачная функция не вызывалась недавно (или когда одновременные вызовы превышают доступные "теплые" экземпляры), платформа должна:
- Выделить новую среду выполнения (микро-ВМ или контейнер)
- Загрузить и извлечь ваш пакет развертывания
- Инициализировать среду выполнения (Node.js, Python и т.д.)
- Выполнить ваш код инициализации (импорт модулей, настройка SDK, подключения к БД)
- Выполнить фактический обработчик функции
Шаги 1-3 — это накладные расходы платформы. На шаге 4 ваш выбор кода имеет огромное значение.
Показатели холодного старта на практике
Вот время холодного старта, которое я измерял на разных платформах и в разных конфигурациях в реальных проектах:
| Платформа | Среда выполнения | Размер пакета | Холодный старт |
|---|---|---|---|
| AWS Lambda | Node.js 20 | 5 МБ | 250-400 мс |
| AWS Lambda | Node.js 20 | 50 МБ | 800-1200 мс |
| AWS Lambda | Python 3.12 | 10 МБ | 400-600 мс |
| Firebase Functions v2 | Node.js 20 | 15 МБ | 600-1000 мс |
| Cloudflare Workers | JavaScript | 1 МБ | 0-5 мс |
| Google Cloud Functions v2 | Node.js 20 | 10 МБ | 300-500 мс |
Cloudflare Workers являются исключением, потому что они используют изоляты V8 вместо контейнеров, что полностью исключает штраф за запуск контейнера. Компромисс заключается в более ограниченной среде выполнения.
Смягчение холодных стартов
Есть несколько стратегий, которые действительно помогают:
Зарезервированная параллельность (Lambda): Поддерживает N экземпляров в "теплом" состоянии постоянно. Стоит $0.0000041667 за ГБ-секунду зарезервированной мощности. Для функции 256 МБ это около $3.20/месяц за один "теплый" экземпляр. Стоит того для конечных точек, чувствительных к задержкам.
Минимальное количество экземпляров (Cloud Run, Firebase Functions v2): Та же концепция, другое название. Cloud Run взимает плату за простаивающие экземпляры по сниженной ставке.
Уменьшение размера пакета: Это имеет самое высокое соотношение влияния к усилиям. Tree-shaking, исключение зависимостей для разработки и использование более легких клиентов SDK значительно сокращают время инициализации.
// Плохо: импортирует весь AWS SDK (добавляет 40 МБ+ к пакету)
import AWS from 'aws-sdk';
// Хорошо: импортирует только клиент S3 (добавляет ~3 МБ)
import { S3Client, GetObjectCommand } from '@aws-sdk/client-s3';
Ленивая инициализация: Не устанавливайте соединения с базой данных и не загружайте тяжелые ресурсы в области видимости модуля. Инициализируйте их при первом вызове и повторно используйте при последующих "теплых" вызовах.
import { Pool } from 'pg';
let pool: Pool | null = null;
function getPool(): Pool {
if (!pool) {
pool = new Pool({
connectionString: process.env.DATABASE_URL,
max: 1, // Одно соединение на экземпляр Lambda
});
}
return pool;
}
export async function handler(event: APIGatewayEvent) {
const db = getPool();
const result = await db.query('SELECT * FROM users WHERE id = $1', [event.pathParameters?.id]);
return { statusCode: 200, body: JSON.stringify(result.rows[0]) };
}
Сравнение стоимости при разных масштабах
Стоимость — это то, где разговор становится интересным, потому что экономика меняется с ростом трафика.
Низкий трафик (1 000 - 50 000 запросов/день)
При таком масштабе бессерверная архитектура почти всегда дешевле. Сюда попадают многие стартапы и побочные проекты.
Стоимость Lambda для 30 000 запросов/день, средняя длительность 200 мс, 256 МБ памяти:
- Плата за запросы: 900 тыс. запросов/месяц x $0.20/миллион = $0.18
- Плата за вычисления: 900 тыс. x 0.2 с x 0.25 ГБ x $0.0000166667 = $0.75
- Итого: ~$1/месяц
Эквивалентный традиционный сервер (t4g.small на AWS):
- По требованию: $12.26/месяц
- С планом экономии на 1 год: ~$8/месяц
При низком трафике вы платите за постоянно работающий сервер, который на 95% простаивает.
Средний трафик (100 000 - 1 000 000 запросов/день)
Это зона пересечения, где сравнение становится близким.
Стоимость Lambda для 500 000 запросов/день, средняя длительность 200 мс, 256 МБ:
- Плата за запросы: 15 млн/месяц x $0.20/миллион = $3.00
- Плата за вычисления: 15 млн x 0.2 с x 0.25 ГБ x $0.0000166667 = $12.50
- Итого: ~$15.50/месяц
t4g.medium (2 vCPU, 4 ГБ ОЗУ):
- По требованию: $24.53/месяц
- С планом экономии: ~$16/месяц
Затраты сопоставимы, но традиционный сервер обрабатывает этот трафик со значительным запасом. Если ваш трафик стабилен, сервер немного дешевле. Если ваш трафик пиковый (много в будние дни, всплески, вызванные событиями), то оплата Lambda за вызов означает, что вы не платите за периоды затишья.
Высокий трафик (5 000 000+ запросов/день)
При таком масштабе бессерверная архитектура почти всегда дороже для устойчивых рабочих нагрузок.
Стоимость Lambda для 5 000 000 запросов/день, средняя длительность 200 мс, 512 МБ:
- Плата за запросы: 150 млн/месяц x $0.20/миллион = $30
- Плата за вычисления: 150 млн x 0.2 с x 0.5 ГБ x $0.0000166667 = $250
- Итого: ~$280/месяц
c6g.large (2 vCPU, 4 ГБ ОЗУ) с группой автомасштабирования:
- 2 экземпляра с планом экономии: ~$60/месяц
- С балансировщиком нагрузки: ~$16/месяц
- Итого: ~$76/месяц
Традиционный подход в 3.7 раза дешевле при таком масштабе, и разрыв увеличивается с ростом трафика.
Скрытые расходы, которые необходимо учитывать
Биллинг Lambda — это не вся картина. Добавьте API Gateway ($1-3.50 за миллион запросов), CloudWatch Logs ($0.50/ГБ принятых данных) и трассировку X-Ray, если вы ее используете. С традиционной стороны добавьте расходы на балансировщик нагрузки, мониторинг и время на операции по управлению экземплярами и развертываниями.
Различия в опыте разработчика
DX бессерверной архитектуры
Преимущества:
- Отсутствие необходимости управлять инфраструктурой (без патчей, без настройки масштабирования)
- Развертывание по функциям означает меньший радиус поражения
- Локальная разработка с эмуляторами (Firebase Emulator Suite, SAM CLI, Serverless Framework offline)
- Встроенная наблюдаемость через логирование и трассировку платформы
Болевые точки:
- Локальная разработка никогда не соответствует производственному поведению идеально
- Отладка распределенных вызовов функций между собой сложнее, чем пошаговая отладка монолита
- Ограничения на размер развертывания (Lambda: 250 МБ в распакованном виде) ограничивают выбор зависимостей
- Настройка IAM и разрешений многословна и легко ошибиться
- Холодные старты замедляют циклы итеративной разработки при тестировании развернутых функций
DX традиционного бэкенда
Преимущества:
- Локальная среда разработки — это производственная среда (тот же процесс, то же состояние)
- Отладка проста — подключите отладчик, установите точки останова, пошагово выполняйте код
- Нет ограничений на размер развертывания
- Шаблоны промежуточного ПО, хуки жизненного цикла запроса и глобальная обработка ошибок естественны
- Поддержка WebSocket, долгоживущие процессы и фоновые задачи работают без дополнительных сервисов
Болевые точки:
- Вы управляете жизненным циклом инфраструктуры (обновления, масштабирование, проверки работоспособности)
- Развертывания требуют оркестровки (постепенные обновления, льготные периоды проверки работоспособности)
- Масштабирование требует настройки (группы автомасштабирования, оркестровка контейнеров)
- Мониторинг и логирование требуют явной настройки
Разрыв между фреймворками сокращается
Фреймворки, такие как SST (Serverless Stack) и Architect, значительно улучшили DX бессерверной архитектуры. SST, в частности, предоставляет режим разработки "Live Lambda", где ваш локально запущенный код обрабатывает вызовы Lambda в реальном времени, полностью исключая цикл развертывания-тестирования.
С традиционной стороны, платформы, такие как Railway, Fly.io и Render, упростили развертывание до git push. Операционная нагрузка по запуску традиционного бэкенда значительно снизилась.
Когда бессерверная архитектура выигрывает
Событийные рабочие нагрузки
Если ваш код выполняется в ответ на события — загрузку файлов, изменения в базе данных, сообщения из очереди, запланированные задачи — бессерверная архитектура является естественным выбором. Вы не поддерживаете цикл опроса или процесс прослушивания. Платформа запускает ваш код именно тогда, когда это необходимо.
// Firebase Functions: запускается при создании документа Firestore
import { onDocumentCreated } from 'firebase-functions/v2/firestore';
export const onOrderCreated = onDocumentCreated('orders/{orderId}', async (event) => {
const order = event.data?.data();
if (!order) return;
// Отправить электронное письмо с подтверждением
await sendEmail(order.customerEmail, {
template: 'order-confirmation',
data: { orderId: event.params.orderId, items: order.items },
});
// Обновить инвентарь
await updateInventory(order.items);
// Уведомить ресторан
await sendPushNotification(order.restaurantId, {
title: 'Новый заказ',
body: `Получен заказ #${event.params.orderId}`,
});
});
Спорадический или непредсказуемый трафик
Внутренний инструмент, который получает 50 запросов в понедельник утром и 2 запроса в остальное время недели. Приемник вебхуков, который обрабатывает события от стороннего API. Генератор запланированных отчетов, который работает 30 секунд раз в день. Эти рабочие нагрузки имеют почти нулевую стоимость на бессерверной архитектуре и тратят деньги на постоянно работающую инфраструктуру.
Конечные точки API с низким и средним трафиком
Для MVP API стартапа, обслуживающего несколько тысяч запросов в день, бессерверная архитектура предоставляет функциональный бэкенд с минимальными операционными накладными расходами и почти нулевой стоимостью. Вы можете полностью сосредоточиться на бизнес-логике.
Параллельная обработка данных
Нужно обработать 10 000 изображений, перекодировать 500 видео или запустить аналитику на большом наборе данных? Распределите нагрузку на тысячи одновременных вызовов Lambda, обрабатывайте параллельно и платите только за использованное время вычислений. Достижение такого же параллелизма с традиционными серверами требует выделения (и оплаты) этой пиковой мощности.
Когда традиционные бэкенды выигрывают
Постоянные соединения
Соединения WebSocket, Server-Sent Events, потоки gRPC и длительный опрос (long-polling) — все они требуют постоянного соединения между клиентом и сервером. Функции Lambda имеют ограничение на выполнение в 15 минут и не предназначены для долгоживущих соединений.
Вы можете обойти это с помощью API Gateway WebSocket APIs или AWS IoT Core, но сложность и стоимость часто превышают простой сервер WebSocket на Cloud Run или контейнерной платформе.
Сложные конвейеры запросов
Когда запрос проходит через аутентификацию, ограничение скорости, проверку ввода, бизнес-логику, операции с базой данных, обновления кеша, генерацию событий и форматирование ответа — шаблон конвейера промежуточного ПО Express/Fastify/Koa эргономически превосходит плоский шаблон обработчика облачных функций.
// Традиционный: чистый конвейер промежуточного ПО
app.use(cors());
app.use(helmet());
app.use(rateLimiter);
app.use(authenticate);
app.use('/api/v1', apiRouter);
app.use(errorHandler);
Воспроизведение этого в Lambda требует либо фреймворка, такого как Middy (который добавляет вес и сложность), либо дублирования кода настройки между функциями.
Операции с состоянием
Если ваше приложение поддерживает состояние в памяти — кеш, пул соединений, счетчик ограничения скорости, данные сессии — традиционный сервер обрабатывает это естественным образом. Функции Lambda могут повторно использовать состояние при "теплых" вызовах, но вы не можете на это полагаться. Любое состояние, которое должно сохраняться, требует внешнего сервиса (Redis, DynamoDB), что добавляет задержку и стоимость.
Жесткие требования к задержке
Для API, где каждая миллисекунда имеет значение — торги в реальном времени, игровые серверы, финансовые транзакции — непредсказуемая задержка, вызванная холодными стартами, неприемлема, даже с зарезервированной параллельностью. Хорошо настроенный серверный процесс с пулом соединений и "теплыми" кешами обеспечивает стабильное время отклика менее 10 мс, что бессерверная архитектура гарантировать не может.
Гибридный подход
На практике большинство производственных систем, которые я создаю, в конечном итоге становятся гибридными. Основной API работает на традиционном бэкенде (Cloud Run или контейнерная платформа), в то время как вспомогательные рабочие нагрузки выполняются на облачных функциях.
Практическая гибридная архитектура
Клиент
│
├─→ API Gateway / Балансировщик нагрузки
│ └─→ Cloud Run (основной API)
│ ├─→ PostgreSQL (Cloud SQL)
│ ├─→ Redis (Memorystore)
│ └─→ Pub/Sub (шина событий)
│
└─→ Cloud Functions (обработчики событий)
├─→ Обработка изображений (при загрузке)
├─→ Отправка электронной почты (при создании заказа)
├─→ Агрегация аналитики (по расписанию)
└─→ Обработка вебхуков (HTTP-триггер)
Основной API обрабатывает синхронный трафик запрос-ответ с постоянными подключениями к базе данных, кешированием в памяти и стабильной задержкой. Облачные функции обрабатывают асинхронные, событийные рабочие нагрузки, где холодные старты не имеют значения, потому что пользователь не ждет ответа.
Стратегия миграции: от традиционного к бессерверному
Если у вас есть существующий традиционный бэкенд и вы хотите выборочно внедрить бессерверную архитектуру:
- Определите событийные операции, которые в настоящее время выполняются как фоновые задачи, cron-задачи или потребители очередей. Их легче всего мигрировать.
- Извлеките независимые конечные точки, которые не разделяют состояние с другими конечными точками. Конечные точки проверки работоспособности, приемники вебхуков и служебные API являются хорошими кандидатами.
- Оставьте основной API традиционным, если у вас нет веской причины для его декомпозиции. Операционные накладные расходы на управление 50 функциями Lambda часто превышают управление одним контейнером.
- Используйте шину событий (Pub/Sub, EventBridge, SQS) в качестве слоя интеграции между вашим традиционным API и бессерверными функциями. API публикует события; функции подписываются и реагируют.
Стратегия миграции: от бессерверного к традиционному
Переход в другом направлении иногда необходим, когда бессерверный API перерастает свою архитектуру:
- Не переписывайте все сразу. Начните с консолидации функций с самым высоким трафиком в один сервер API.
- Оставьте событийные функции как функции. Мигрируйте только обработчики запрос-ответ.
- Используйте те же маршруты API. Направьте ваш API Gateway/балансировщик нагрузки на новый сервер для мигрированных маршрутов и продолжайте маршрутизацию в Lambda для остальных.
- Сначала мигрируйте подключения к базе данных. Самый большой выигрыш в производительности — это переход от настройки соединения для каждого вызова к постоянному пулу соединений.
Заметки по конкретным платформам
Firebase Functions (v2)
Firebase Functions v2 работает на Cloud Run, что дает ему значительные преимущества по сравнению с v1: настраиваемая параллельность (несколько запросов на экземпляр), минимальное количество экземпляров, более длительные тайм-ауты (до 60 минут) и большее выделение памяти. Если вы используете функции Firebase v1, обновление до v2 стоит усилий по миграции.
Firebase Emulator Suite обеспечивает лучший опыт локальной разработки в бессерверном пространстве. Он эмулирует Firestore, Auth, Storage и Functions в единой локальной среде с горячей перезагрузкой при изменениях кода.
AWS Lambda
Lambda имеет самую глубокую экосистему интеграции — триггеры практически от каждого сервиса AWS, слои для общего кода и SnapStart для рабочих нагрузок Java. Функция URL-адреса функции устраняет необходимость в API Gateway для простых случаев использования, экономя $3.50 за миллион запросов.
Lambda@Edge и CloudFront Functions мощны для манипулирования запросами/ответами на уровне CDN, но опыт разработки и отладки значительно хуже, чем у стандартной Lambda.
Cloud Run
Cloud Run стирает грань между бессерверным и традиционным. Он запускает контейнеры (любой язык, любой фреймворк), масштабируется до нуля и поддерживает параллельность (несколько запросов на экземпляр). Он бессерверный по модели биллинга, но традиционный по модели выполнения. Для команд, которые хотят экономику бессерверной архитектуры без переписывания своего кода в виде обработчиков функций, Cloud Run часто является правильным ответом.
Принятие решения
Вот схема принятия решений, которую я использую:
- Является ли рабочая нагрузка событийной и асинхронной? Бессерверная.
- Трафик низкий и непредсказуемый? Бессерверная.
- Нужны ли постоянные соединения или состояние в памяти? Традиционная.
- Критична ли стабильно низкая задержка? Традиционная.
- Команда небольшая и не любит операции? Бессерверная (или Cloud Run).
- Трафик высокий и стабильный? Традиционная (дешевле).
- Это смесь вышеперечисленного? Гибридная.
Худшее решение — рассматривать это как выбор "все или ничего". Используйте правильный инструмент для каждой рабочей нагрузки, соединяйте их через четко определенные интерфейсы, и вы получите преимущества обоих, не привязываясь полностью ни к одному из них.