Настройка CI/CD-конвейера, который действительно работает в продакшене
Проверенные в бою паттерны CI/CD для реальных проектов — от рабочих процессов GitHub Actions до стратегий развертывания, которые не сломают продакшен в пятницу.
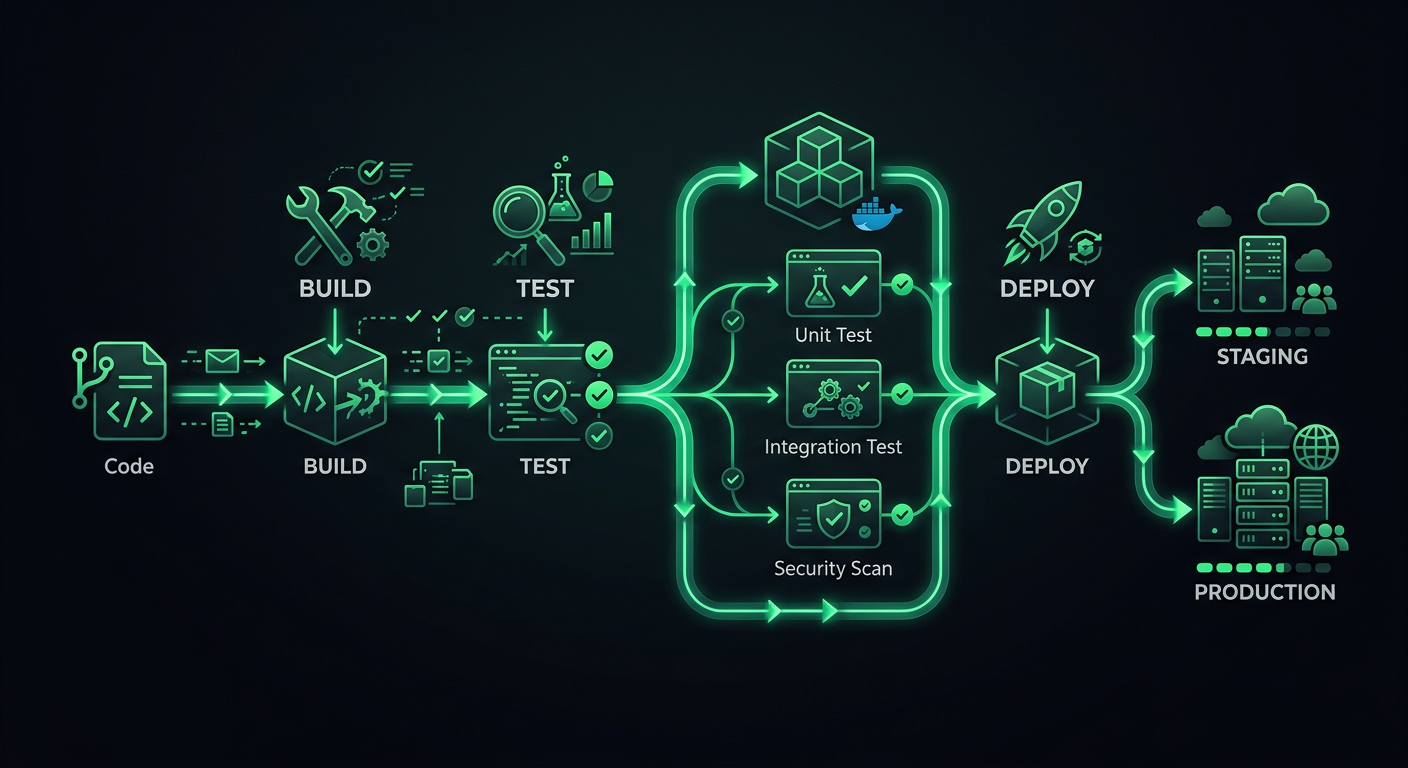
Первый CI/CD-конвейер, который я настроил для продакшен-проекта, представлял собой один рабочий процесс GitHub Actions, который запускал npm test, а затем развертывал код на VPS через SSH. Он работал, пока не перестал — неудачное развертывание оставило сервер в полуобновленном состоянии в пятницу вечером, и я провел выходные, вручную откатывая файлы. Этот опыт научил меня, что конвейер развертывания — это не просто «запустить тесты, а затем развернуть». Это целая система проверок, шлюзов и механизмов отката, которые стоят между git push и тем, как ваши пользователи видят новый код.
В этом посте рассматривается архитектура конвейера, которую я оттачивал на нескольких продакшен-проектах, с конкретными примерами GitHub Actions, которые вы можете адаптировать.
Архитектура конвейера
Продакшен-конвейер имеет отдельные этапы, и каждый этап имеет определенную цель. Пропуск этапов экономит минуты сейчас и стоит часов позже.
Этапы
Code Push
│
├─→ Stage 1: Validation (lint, format, type-check)
│
├─→ Stage 2: Testing (unit, integration)
│
├─→ Stage 3: Build (compile, bundle, containerize)
│
├─→ Stage 4: Deploy to Staging
│
├─→ Stage 5: Smoke Tests / E2E on Staging
│
└─→ Stage 6: Deploy to Production
Каждый этап действует как шлюз. Если валидация не удалась, тесты никогда не запускаются. Если тесты не удались, сборка никогда не начинается. Это экономит вычислительное время и обеспечивает быструю обратную связь — разработчики узнают в течение 30 секунд, если они забыли запустить линтер, вместо того чтобы ждать 8 минут, пока набор тестов не завершится с ошибкой.
Стратегия запуска
Не каждый push требует полного конвейера. Вот конфигурация запуска, которую я использую:
# .github/workflows/ci.yml
name: CI
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
types: [opened, synchronize, reopened]
Пулл-реквесты запускают этапы 1-3 (валидация, тестирование, сборка). Слияния в develop развертываются на стейджинг. Слияния в main развертываются в продакшен. Это обеспечивает быструю обратную связь по PR, гарантируя, что развертывания происходят только из защищенных веток.
Этап 1: Валидация
Валидация выявляет несоответствия форматирования и ошибки типов до запуска тестов. Эти проверки выполняются быстро (менее 30 секунд) и выявляют наиболее распространенные проблемы.
jobs:
validate:
name: Validate
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Check formatting
run: npx prettier --check "src/**/*.{ts,tsx,js,jsx,json,css}"
- name: Lint
run: npx eslint src/ --max-warnings 0
- name: Type check
run: npx tsc --noEmit
Правило --max-warnings 0
ESLint различает ошибки (которые прерывают процесс) и предупреждения (которые не прерывают). Без --max-warnings 0 команды накапливают сотни предупреждений, которые все игнорируют. Обработка предупреждений как ошибок в CI заставляет команду либо исправлять их, либо явно отключать правило. Золотой середины нет.
Форматирование как проверка CI, а не просто рекомендация
Запуск Prettier в CI (с --check, а не --write) обеспечивает единообразное форматирование, не полагаясь на то, что у каждого разработчика есть правильное расширение редактора. Если форматирование не проходит в CI, разработчик запускает npx prettier --write . локально и фиксирует исправление. Это не подлежит обсуждению — споры о форматировании заканчиваются, когда инструмент принимает решения.
Этап 2: Тестирование
Тестирование — это основа конвейера. Я разделяю тесты на параллельные задачи по типу для более быстрой обратной связи.
unit-tests:
name: Unit Tests
runs-on: ubuntu-latest
needs: validate
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run unit tests
run: npx vitest run --coverage --reporter=verbose
- name: Upload coverage report
if: always()
uses: actions/upload-artifact@v4
with:
name: coverage-report
path: coverage/
integration-tests:
name: Integration Tests
runs-on: ubuntu-latest
needs: validate
services:
postgres:
image: postgres:16
env:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
POSTGRES_DB: testdb
ports:
- 5432:5432
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
redis:
image: redis:7
ports:
- 6379:6379
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run database migrations
run: npx prisma migrate deploy
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
- name: Run integration tests
run: npx vitest run --config vitest.integration.config.ts
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
REDIS_URL: redis://localhost:6379
Сервисные контейнеры для интеграционных тестов
Сервисные контейнеры GitHub Actions используются недостаточно. Вместо того чтобы мокать вашу базу данных в интеграционных тестах (что тестирует мок, а не ваш код), запустите реальный экземпляр PostgreSQL. Блок services управляет жизненным циклом — контейнер запускается до ваших тестов и останавливается после.
Это добавляет около 15-20 секунд к задаче для запуска контейнера, но уверенность, которую вы получаете от тестирования на реальной базе данных, того стоит.
Параллельное выполнение тестов
Модульные и интеграционные тесты выполняются параллельно (оба needs: validate, а не needs: unit-tests). Это сокращает общее время конвейера. Если ваши модульные тесты занимают 2 минуты, а интеграционные — 4 минуты, параллельное выполнение означает, что вы ждете 4 минуты вместо 6.
Этап 3: Сборка
Этап сборки проверяет, что проект компилируется и производит артефакты, готовые к развертыванию.
build:
name: Build
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Build application
run: npm run build
env:
NODE_ENV: production
- name: Upload build artifacts
uses: actions/upload-artifact@v4
with:
name: build-output
path: dist/
retention-days: 7
Кэширование сборки
Для развертываний на основе Docker кэширование слоев значительно ускоряет сборки:
build-docker:
name: Build Docker Image
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to Container Registry
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v6
with:
context: .
push: ${{ github.event_name != 'pull_request' }}
tags: |
ghcr.io/${{ github.repository }}:${{ github.sha }}
ghcr.io/${{ github.repository }}:latest
cache-from: type=gha
cache-to: type=gha,mode=max
Параметр cache-from: type=gha использует кэш GitHub Actions для хранения слоев Docker между запусками. Для типичного приложения Node.js это сокращает время сборки с 3-4 минут до 30-60 секунд для изменений, затрагивающих только зависимости.
Лучшие практики Dockerfile для CI
Структура Dockerfile напрямую влияет на эффективность кэша сборки. Располагайте слои от наименее часто изменяемых к наиболее часто изменяемым:
FROM node:20-alpine AS base
# System dependencies (rarely changes)
RUN apk add --no-cache libc6-compat
# Package manifests (changes when dependencies change)
WORKDIR /app
COPY package.json package-lock.json ./
# Install dependencies (cached unless manifests change)
FROM base AS deps
RUN npm ci --production
FROM base AS build
RUN npm ci
COPY . .
RUN npm run build
# Production image
FROM node:20-alpine AS runner
WORKDIR /app
ENV NODE_ENV=production
COPY --from=deps /app/node_modules ./node_modules
COPY --from=build /app/dist ./dist
COPY --from=build /app/package.json ./
EXPOSE 3000
CMD ["node", "dist/server.js"]
Многоступенчатые сборки сохраняют конечный образ небольшим (без зависимостей для разработки, без исходного кода), а порядок слоев гарантирует, что npm ci запускается только при изменении package.json или package-lock.json.
Этап 4: Развертывание на стейджинг
Развертывание на стейджинг происходит автоматически при слиянии в ветку develop. Стейджинг-среда должна максимально точно имитировать продакшен — та же инфраструктура, те же переменные окружения (с разными значениями), та же конфигурация масштабирования.
deploy-staging:
name: Deploy to Staging
runs-on: ubuntu-latest
needs: build
if: github.ref == 'refs/heads/develop' && github.event_name == 'push'
environment:
name: staging
url: https://staging.example.com
steps:
- uses: actions/checkout@v4
- name: Download build artifacts
uses: actions/download-artifact@v4
with:
name: build-output
path: dist/
- name: Deploy to Cloud Run (Staging)
uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-staging
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
env_vars: |
NODE_ENV=staging
DATABASE_URL=${{ secrets.STAGING_DATABASE_URL }}
Среды GitHub
Ключ environment в рабочем процессе включает правила защиты среды GitHub. Вы можете требовать ручного подтверждения, ограничивать ветки, которые могут развертываться, и устанавливать секреты, специфичные для среды. Для стейджинга я обычно не требую подтверждения (автоматическое развертывание). Для продакшена я требую как минимум одного рецензента.
Этап 5: Дымовые тесты
После развертывания на стейджинг запустите базовый набор тестов для развернутого приложения, чтобы убедиться, что оно действительно работает в реальной среде.
smoke-tests:
name: Smoke Tests
runs-on: ubuntu-latest
needs: deploy-staging
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Wait for deployment
run: |
for i in {1..30}; do
status=$(curl -s -o /dev/null -w "%{http_code}" https://staging.example.com/health)
if [ "$status" = "200" ]; then
echo "Service is healthy"
exit 0
fi
echo "Waiting for service... (attempt $i)"
sleep 10
done
echo "Service did not become healthy"
exit 1
- name: Run smoke tests
run: npx playwright test --config=playwright.smoke.config.ts
env:
BASE_URL: https://staging.example.com
Дымовые тесты — это не полноценные E2E-тесты. Они проверяют критические пути: загружается ли домашняя страница, может ли пользователь войти в систему, возвращает ли основная конечная точка API данные. Пять-десять сценариев, которые занимают менее 2 минут. Если дымовые тесты не пройдены, развертывание на стейджинг откатывается, и развертывание в продакшен не продолжается.
Этап 6: Развертывание в продакшен
Развертывание в продакшен — это то место, где стратегия развертывания имеет наибольшее значение. Существует несколько подходов, каждый из которых имеет свои компромиссы.
Последовательное развертывание
Самая простая стратегия. Новые экземпляры запускаются, пока старые экземпляры выводятся из эксплуатации. В любой момент во время развертывания некоторые запросы попадают на старую версию, а некоторые — на новую. Это поведение по умолчанию для большинства контейнерных платформ.
Плюсы: Простота, отсутствие дополнительных затрат на инфраструктуру. Минусы: Две версии обслуживают трафик одновременно, что может вызвать проблемы с изменениями схемы базы данных или изменениями контракта API.
Сине-зеленое развертывание
Существуют две идентичные среды (синяя и зеленая). Одна обслуживает трафик, пока другая простаивает. Развернитесь в простаивающей среде, убедитесь, что она работает, затем переключите маршрутизатор. Если что-то пойдет не так, переключитесь обратно.
deploy-production:
name: Deploy to Production
runs-on: ubuntu-latest
needs: smoke-tests
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
environment:
name: production
url: https://api.example.com
steps:
- name: Deploy new revision
uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-production
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
flags: '--no-traffic'
- name: Run production health check
run: |
REVISION_URL=$(gcloud run revisions describe my-api-production-${{ github.sha }} \
--region us-central1 --format='value(status.url)')
status=$(curl -s -o /dev/null -w "%{http_code}" "$REVISION_URL/health")
if [ "$status" != "200" ]; then
echo "Health check failed"
exit 1
fi
- name: Migrate traffic
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
Флаг --no-traffic развертывает новую ревизию, не направляя на нее трафик. После прохождения проверки работоспособности трафик переключается на новую ревизию. Если проверка работоспособности не удалась, рабочий процесс останавливается, и старая ревизия продолжает обслуживать запросы.
Канареечное развертывание
Направьте небольшой процент трафика (5-10%) на новую версию, одновременно отслеживая частоту ошибок, задержку и ключевые бизнес-метрики. Если метрики выглядят хорошо после определенного периода, постепенно увеличивайте трафик. Если метрики ухудшаются, откатитесь.
- name: Canary - route 10% of traffic
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=my-api-production-${{ github.sha }}=10
- name: Monitor canary (5 minutes)
run: |
sleep 300
# Check error rate for the canary revision
ERROR_RATE=$(curl -s "$MONITORING_API/error-rate?revision=${{ github.sha }}")
if (( $(echo "$ERROR_RATE > 1.0" | bc -l) )); then
echo "Error rate too high: $ERROR_RATE%. Rolling back."
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
exit 1
fi
- name: Promote canary to 100%
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
Когда использовать канареечное развертывание: Когда у вас достаточно трафика, чтобы 10% все еще генерировали статистически значимые показатели ошибок. Для сервиса, обрабатывающего 100 запросов в минуту, 10% дают 10 запросов в минуту — этого достаточно для обнаружения повышенной частоты ошибок в течение нескольких минут. Для сервиса, обрабатывающего 10 запросов в минуту, канареечные развертывания не имеют смысла.
Механизмы отката
Каждое развертывание должно иметь задокументированный путь отката. «Повторное развертывание старой версии» — это стратегия отката, но она медленная. Лучшие варианты:
Мгновенный откат через переключение трафика
Если вы развертываете с --no-traffic и переключаете трафик, откат выполняется одной командой:
# Roll back to the previous revision
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=PREVIOUS_REVISION=100
Это вступает в силу за секунды, потому что старая ревизия все еще работает.
Автоматический откат
Добавьте шаг мониторинга после развертывания, который автоматически откатывается, если частота ошибок резко возрастает:
- name: Post-deploy monitor
run: |
for i in {1..10}; do
sleep 60
ERROR_RATE=$(curl -s "$MONITORING_API/error-rate?window=5m")
if (( $(echo "$ERROR_RATE > 2.0" | bc -l) )); then
echo "Error rate $ERROR_RATE% exceeds threshold. Rolling back."
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=$PREVIOUS_REVISION=100
exit 1
fi
echo "Minute $i: Error rate $ERROR_RATE% — OK"
done
Откат миграции базы данных
Это самая сложная часть. Если ваше развертывание включает изменения схемы базы данных, откат приложения без отката базы данных создает несоответствие. Решение — миграции с расширением и сжатием:
- Расширение: Добавьте новые столбцы/таблицы, не удаляя старые. Сделайте новые столбцы допускающими NULL или со значениями по умолчанию.
- Развертывание: Новый код записывает данные как в старые, так и в новые столбцы. Читает из новых столбцов с возвратом к старым.
- Миграция данных: Заполните новые столбцы данными из старых.
- Сжатие: После проверки разверните код, который использует только новые столбцы. Затем удалите старые столбцы.
Это делает каждый шаг независимо обратимым.
Управление секретами
Никогда не хардкодьте секреты. Никогда не коммитьте файлы .env. Вот как я обрабатываю секреты в GitHub Actions:
Секреты GitHub
В большинстве случаев встроенных секретов GitHub достаточно. Они зашифрованы, никогда не отображаются в логах и ограничены репозиториями или организациями.
env:
DATABASE_URL: ${{ secrets.DATABASE_URL }}
API_KEY: ${{ secrets.API_KEY }}
Секреты, привязанные к среде
Различные секреты для стейджинга и продакшена:
deploy-staging:
environment: staging
# ${{ secrets.DATABASE_URL }} resolves to the staging value
deploy-production:
environment: production
# ${{ secrets.DATABASE_URL }} resolves to the production value
Внешние менеджеры секретов
Для больших команд или более строгих требований соответствия используйте AWS Secrets Manager, Google Secret Manager или HashiCorp Vault. Приложение получает секреты во время выполнения, а не в виде переменных окружения.
import { SecretManagerServiceClient } from '@google-cloud/secret-manager';
const client = new SecretManagerServiceClient();
async function getSecret(name: string): Promise<string> {
const [version] = await client.accessSecretVersion({
name: `projects/my-project/secrets/${name}/versions/latest`,
});
return version.payload?.data?.toString() || '';
}
Мониторинг развертываний
Развертывание не завершено, когда код запущен. Оно завершено, когда вы подтвердили, что код работает.
Уведомления о развертывании
Отправляйте события развертывания в Slack с соответствующим контекстом:
- name: Notify Slack
if: always()
uses: slackapi/slack-github-action@v2
with:
webhook: ${{ secrets.SLACK_WEBHOOK }}
webhook-type: incoming-webhook
payload: |
{
"text": "${{ job.status == 'success' && 'Deployed' || 'Failed to deploy' }} `${{ github.sha }}` to production",
"blocks": [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*${{ job.status == 'success' && ':white_check_mark: Deployment Successful' || ':x: Deployment Failed' }}*\nCommit: `${{ github.sha }}`\nAuthor: ${{ github.actor }}\nMessage: ${{ github.event.head_commit.message }}"
}
}
]
}
Проверки работоспособности после развертывания
После каждого развертывания в продакшен проверяйте, что критические конечные точки отвечают правильно:
- name: Verify production health
run: |
endpoints=("/" "/api/health" "/api/v1/status")
for endpoint in "${endpoints[@]}"; do
status=$(curl -s -o /dev/null -w "%{http_code}" "https://api.example.com$endpoint")
if [ "$status" != "200" ]; then
echo "FAILED: $endpoint returned $status"
exit 1
fi
echo "OK: $endpoint returned $status"
done
Пример полного конвейера
Собирая все воедино, вот сокращенный, но полный конвейер для приложения Node.js, развернутого в Cloud Run:
name: CI/CD Pipeline
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: ${{ github.event_name == 'pull_request' }}
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx prettier --check "src/**/*.{ts,tsx}"
- run: npx eslint src/ --max-warnings 0
- run: npx tsc --noEmit
test:
needs: validate
runs-on: ubuntu-latest
services:
postgres:
image: postgres:16
env: { POSTGRES_USER: test, POSTGRES_PASSWORD: test, POSTGRES_DB: testdb }
ports: ['5432:5432']
options: --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx vitest run --coverage
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
build-and-push:
needs: test
if: github.event_name == 'push'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: docker/setup-buildx-action@v3
- uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- uses: docker/build-push-action@v6
with:
context: .
push: true
tags: ghcr.io/${{ github.repository }}:${{ github.sha }}
cache-from: type=gha
cache-to: type=gha,mode=max
deploy:
needs: build-and-push
runs-on: ubuntu-latest
environment:
name: ${{ github.ref == 'refs/heads/main' && 'production' || 'staging' }}
steps:
- uses: google-github-actions/auth@v2
with:
credentials_json: ${{ secrets.GCP_SA_KEY }}
- uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-${{ github.ref == 'refs/heads/main' && 'prod' || 'staging' }}
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
Стоит отметить блок concurrency — он отменяет выполняющиеся запуски для одной и той же ветки в пулл-реквестах, поэтому отправка исправления, пока CI все еще работает, не ставит в очередь два конвейера.
Что бы я сделал по-другому, начиная заново
Если бы я сегодня настраивал конвейер с нуля, я бы начал только с этапов валидации и тестирования — без автоматизации развертывания. Развертывал бы вручную (или с помощью простого скрипта развертывания) в течение первых нескольких недель, пока кодовая база стабилизируется. Добавлял бы автоматизацию развертывания только тогда, когда ручной процесс станет узким местом, а не раньше. Преждевременная оптимизация конвейера так же реальна, как и преждевременная оптимизация кода, а отладка сломанного конвейера развертывания в 2 часа ночи значительно хуже, чем запуск ./deploy.sh вручную.
Связанные проекты
RestoHub
Рестораны перестают терять 30% в пользу Uber Eats — они получают собственную систему заказов, меню, сайт и программу лояльности в одной платформе. Полноценный опыт уровня Uber Eats, но ресторан оставляет себе каждый доллар.
TakeCare
Одна медсестра теперь удалённо мониторит 250 пациентов — заменяя ручные телефонные звонки и домашние визиты в крупнейших больницах Квебека. Работает в Jewish General, CHUM и Douglas Mental Health Institute.