Configuração de Pipeline CI/CD Que Realmente Funciona em Produção
Padrões de CI/CD testados em batalha para projetos reais — desde workflows do GitHub Actions até estratégias de deploy que não quebram a produção na sexta-feira.
O primeiro pipeline de CI/CD que configurei para um projeto em produção era um único workflow do GitHub Actions que executava npm test e então fazia deploy para um VPS via SSH. Funcionou até não funcionar mais — um deploy falho deixou o servidor em um estado meio atualizado numa sexta-feira à noite, e eu passei o fim de semana revertendo arquivos manualmente. Essa experiência me ensinou que um pipeline de deploy não é apenas "rodar testes e depois fazer deploy". É todo o sistema de verificações, portões e mecanismos de rollback que ficam entre um git push e seus usuários vendo o código novo.
Este post cobre a arquitetura de pipeline que refinei em múltiplos projetos de produção, com exemplos concretos de GitHub Actions que você pode adaptar.
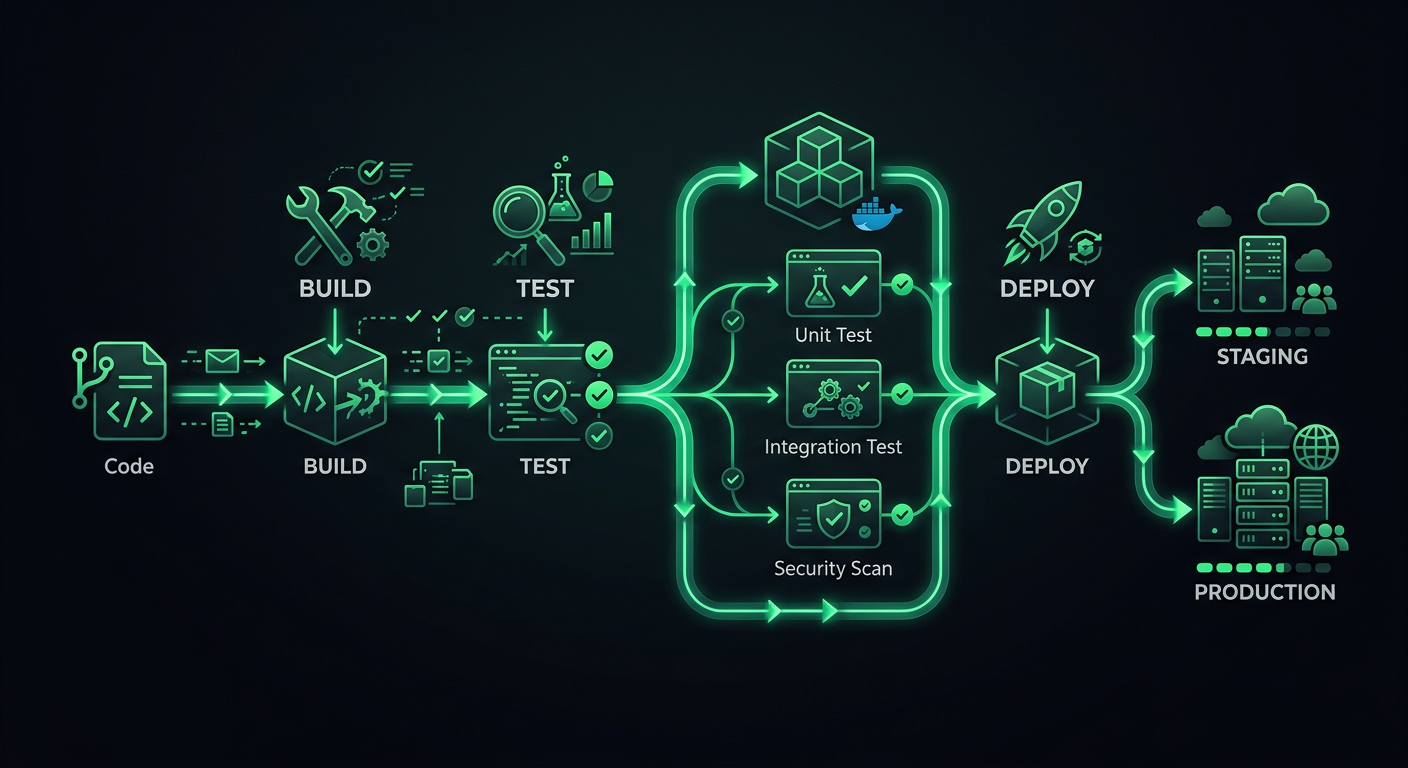
Arquitetura do Pipeline
Um pipeline de produção tem estágios distintos, e cada estágio tem um propósito específico. Pular estágios economiza minutos agora e custa horas depois.
Os Estágios
Code Push
│
├─→ Estágio 1: Validação (lint, formatação, type-check)
│
├─→ Estágio 2: Testes (unitários, integração)
│
├─→ Estágio 3: Build (compilar, empacotar, containerizar)
│
├─→ Estágio 4: Deploy para Staging
│
├─→ Estágio 5: Smoke Tests / E2E no Staging
│
└─→ Estágio 6: Deploy para Produção
Cada estágio atua como um portão. Se a validação falhar, os testes nunca rodam. Se os testes falharem, o build nunca começa. Isso economiza tempo de computação e fornece feedback rápido — desenvolvedores sabem em 30 segundos se esqueceram de rodar o linter, em vez de esperar 8 minutos para uma suíte de testes falhar.
Estratégia de Triggers
Nem todo push precisa do pipeline completo. Aqui está a configuração de trigger que uso:
# .github/workflows/ci.yml
name: CI
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
types: [opened, synchronize, reopened]
Pull requests rodam os estágios 1-3 (validar, testar, compilar). Merges para develop fazem deploy para staging. Merges para main fazem deploy para produção. Isso mantém o feedback de PR rápido enquanto garante que deploys só aconteçam a partir de branches protegidos.
Estágio 1: Validação
A validação captura inconsistências de formatação e erros de tipo antes dos testes rodarem. Essas verificações são rápidas (menos de 30 segundos) e capturam os problemas mais comuns.
jobs:
validate:
name: Validate
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Check formatting
run: npx prettier --check "src/**/*.{ts,tsx,js,jsx,json,css}"
- name: Lint
run: npx eslint src/ --max-warnings 0
- name: Type check
run: npx tsc --noEmit
A Regra --max-warnings 0
O ESLint distingue entre erros (que falham o processo) e warnings (que não falham). Sem --max-warnings 0, times acumulam centenas de warnings que todos ignoram. Tratar warnings como erros no CI força o time a corrigi-los ou desabilitar explicitamente a regra. Sem meio-termo.
Formatação como Check de CI, Não Apenas uma Sugestão
Rodar Prettier no CI (com --check, não --write) garante formatação consistente sem depender de cada desenvolvedor ter a extensão de editor correta. Se a formatação falhar no CI, o desenvolvedor roda npx prettier --write . localmente e comita a correção. Isso é inegociável — debates de formatação acabam quando uma ferramenta toma as decisões.
Estágio 2: Testes
Os testes são a espinha dorsal do pipeline. Eu divido os testes em jobs paralelos baseados no tipo para feedback mais rápido.
unit-tests:
name: Unit Tests
runs-on: ubuntu-latest
needs: validate
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run unit tests
run: npx vitest run --coverage --reporter=verbose
- name: Upload coverage report
if: always()
uses: actions/upload-artifact@v4
with:
name: coverage-report
path: coverage/
integration-tests:
name: Integration Tests
runs-on: ubuntu-latest
needs: validate
services:
postgres:
image: postgres:16
env:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
POSTGRES_DB: testdb
ports:
- 5432:5432
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
redis:
image: redis:7
ports:
- 6379:6379
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run database migrations
run: npx prisma migrate deploy
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
- name: Run integration tests
run: npx vitest run --config vitest.integration.config.ts
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
REDIS_URL: redis://localhost:6379
Containers de Serviço para Testes de Integração
Os service containers do GitHub Actions são subutilizados. Em vez de mockar seu banco de dados em testes de integração (o que testa o mock, não seu código), suba uma instância real de PostgreSQL. O bloco services cuida do gerenciamento de ciclo de vida — o container inicia antes dos seus testes e para depois.
Isso adiciona cerca de 15-20 segundos ao job para startup do container, mas a confiança que você ganha ao testar contra um banco de dados real compensa.
Execução Paralela de Testes
Testes unitários e testes de integração rodam em paralelo (ambos needs: validate, não needs: unit-tests). Isso reduz o tempo total do pipeline. Se seus testes unitários levam 2 minutos e testes de integração levam 4 minutos, a execução paralela significa que você espera 4 minutos em vez de 6.
Estágio 3: Build
O estágio de build valida que o projeto compila e produz artefatos implantáveis.
build:
name: Build
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Build application
run: npm run build
env:
NODE_ENV: production
- name: Upload build artifacts
uses: actions/upload-artifact@v4
with:
name: build-output
path: dist/
retention-days: 7
Cache de Build
Para deploys baseados em Docker, o cache de camadas acelera dramaticamente os builds:
build-docker:
name: Build Docker Image
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to Container Registry
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v6
with:
context: .
push: ${{ github.event_name != 'pull_request' }}
tags: |
ghcr.io/${{ github.repository }}:${{ github.sha }}
ghcr.io/${{ github.repository }}:latest
cache-from: type=gha
cache-to: type=gha,mode=max
O cache-from: type=gha usa o cache do GitHub Actions para armazenar camadas Docker entre execuções. Para uma aplicação Node.js típica, isso reduz o tempo de build de 3-4 minutos para 30-60 segundos em mudanças apenas de dependências.
Melhores Práticas de Dockerfile para CI
A estrutura do Dockerfile impacta diretamente a eficiência do cache de build. Ordene as camadas da menos frequentemente alterada para a mais frequentemente alterada:
FROM node:20-alpine AS base
# System dependencies (rarely changes)
RUN apk add --no-cache libc6-compat
# Package manifests (changes when dependencies change)
WORKDIR /app
COPY package.json package-lock.json ./
# Install dependencies (cached unless manifests change)
FROM base AS deps
RUN npm ci --production
FROM base AS build
RUN npm ci
COPY . .
RUN npm run build
# Production image
FROM node:20-alpine AS runner
WORKDIR /app
ENV NODE_ENV=production
COPY --from=deps /app/node_modules ./node_modules
COPY --from=build /app/dist ./dist
COPY --from=build /app/package.json ./
EXPOSE 3000
CMD ["node", "dist/server.js"]
Builds multi-stage mantêm a imagem final pequena (sem dependências de dev, sem código-fonte), e a ordenação das camadas garante que npm ci só rode quando package.json ou package-lock.json mudam.
Estágio 4: Deploy para Staging
O deploy para staging acontece automaticamente em merges para o branch develop. O ambiente de staging deve espelhar a produção o mais próximo possível — mesma infraestrutura, mesmas variáveis de ambiente (com valores diferentes), mesma configuração de escalabilidade.
deploy-staging:
name: Deploy to Staging
runs-on: ubuntu-latest
needs: build
if: github.ref == 'refs/heads/develop' && github.event_name == 'push'
environment:
name: staging
url: https://staging.example.com
steps:
- uses: actions/checkout@v4
- name: Download build artifacts
uses: actions/download-artifact@v4
with:
name: build-output
path: dist/
- name: Deploy to Cloud Run (Staging)
uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-staging
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
env_vars: |
NODE_ENV=staging
DATABASE_URL=${{ secrets.STAGING_DATABASE_URL }}
Ambientes do GitHub
A chave environment no workflow habilita as regras de proteção de ambiente do GitHub. Você pode exigir aprovação manual, restringir quais branches podem fazer deploy e definir secrets específicos por ambiente. Para staging, eu tipicamente não exijo aprovação (auto-deploy). Para produção, exijo pelo menos um revisor.
Estágio 5: Smoke Tests
Após fazer deploy para staging, rode um conjunto básico de testes contra a aplicação implantada para verificar que ela realmente funciona no ambiente real.
smoke-tests:
name: Smoke Tests
runs-on: ubuntu-latest
needs: deploy-staging
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Wait for deployment
run: |
for i in {1..30}; do
status=$(curl -s -o /dev/null -w "%{http_code}" https://staging.example.com/health)
if [ "$status" = "200" ]; then
echo "Service is healthy"
exit 0
fi
echo "Waiting for service... (attempt $i)"
sleep 10
done
echo "Service did not become healthy"
exit 1
- name: Run smoke tests
run: npx playwright test --config=playwright.smoke.config.ts
env:
BASE_URL: https://staging.example.com
Smoke tests não são testes E2E completos. Eles verificam caminhos críticos: a homepage carrega, um usuário consegue fazer login, o endpoint principal da API retorna dados. Cinco a dez cenários que levam menos de 2 minutos. Se os smoke tests falharem, o deploy de staging é revertido e o deploy de produção não prossegue.
Estágio 6: Deploy para Produção
O deploy para produção é onde a estratégia de deploy mais importa. Existem várias abordagens, cada uma com diferentes trade-offs.
Deploy Rolling
A estratégia mais simples. Novas instâncias são iniciadas enquanto instâncias antigas são drenadas. Em qualquer ponto durante o deploy, algumas requisições chegam à versão antiga e outras à versão nova. Este é o padrão para a maioria das plataformas de container.
Prós: Simples, sem custo extra de infraestrutura. Contras: Duas versões servem tráfego simultaneamente, o que pode causar problemas com mudanças de schema de banco de dados ou mudanças de contrato de API.
Deploy Blue-Green
Dois ambientes idênticos (blue e green) existem. Um serve tráfego enquanto o outro fica ocioso. Faça deploy para o ambiente ocioso, verifique se funciona, e então mude o roteador. Se algo der errado, mude de volta.
deploy-production:
name: Deploy to Production
runs-on: ubuntu-latest
needs: smoke-tests
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
environment:
name: production
url: https://api.example.com
steps:
- name: Deploy new revision
uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-production
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
flags: '--no-traffic'
- name: Run production health check
run: |
REVISION_URL=$(gcloud run revisions describe my-api-production-${{ github.sha }} \
--region us-central1 --format='value(status.url)')
status=$(curl -s -o /dev/null -w "%{http_code}" "$REVISION_URL/health")
if [ "$status" != "200" ]; then
echo "Health check failed"
exit 1
fi
- name: Migrate traffic
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
A flag --no-traffic faz deploy da nova revisão sem enviar tráfego para ela. Após o health check passar, o tráfego é direcionado para a nova revisão. Se o health check falhar, o workflow para e a revisão antiga continua servindo.
Deploy Canário
Roteie uma pequena porcentagem do tráfego (5-10%) para a nova versão enquanto monitora taxas de erro, latência e métricas de negócio. Se as métricas parecerem boas após um período definido, aumente gradualmente o tráfego. Se as métricas degradarem, faça rollback.
- name: Canary - route 10% of traffic
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=my-api-production-${{ github.sha }}=10
- name: Monitor canary (5 minutes)
run: |
sleep 300
# Check error rate for the canary revision
ERROR_RATE=$(curl -s "$MONITORING_API/error-rate?revision=${{ github.sha }}")
if (( $(echo "$ERROR_RATE > 1.0" | bc -l) )); then
echo "Error rate too high: $ERROR_RATE%. Rolling back."
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
exit 1
fi
- name: Promote canary to 100%
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
Quando usar canário: Quando você tem tráfego suficiente para que 10% ainda gere taxas de erro estatisticamente significativas. Para um serviço lidando com 100 requisições/minuto, 10% te dá 10 requisições/minuto — suficiente para detectar taxas de erro elevadas em poucos minutos. Para um serviço lidando com 10 requisições/minuto, deploys canário não são significativos.
Mecanismos de Rollback
Todo deploy deve ter um caminho de rollback documentado. "Re-deploy da versão antiga" é uma estratégia de rollback, mas é lenta. Opções melhores:
Rollback Instantâneo via Redirecionamento de Tráfego
Se você fez deploy com --no-traffic e redirecionou o tráfego, rollback é um único comando:
# Roll back to the previous revision
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=PREVIOUS_REVISION=100
Isso entra em efeito em segundos porque a revisão antiga ainda está rodando.
Rollback Automatizado
Adicione um passo de monitoramento pós-deploy que automaticamente faz rollback se as taxas de erro aumentarem:
- name: Post-deploy monitor
run: |
for i in {1..10}; do
sleep 60
ERROR_RATE=$(curl -s "$MONITORING_API/error-rate?window=5m")
if (( $(echo "$ERROR_RATE > 2.0" | bc -l) )); then
echo "Error rate $ERROR_RATE% exceeds threshold. Rolling back."
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=$PREVIOUS_REVISION=100
exit 1
fi
echo "Minute $i: Error rate $ERROR_RATE% — OK"
done
Rollback de Migração de Banco de Dados
Esta é a parte mais difícil. Se seu deploy inclui mudanças de schema do banco de dados, reverter a aplicação sem reverter o banco cria uma incompatibilidade. A solução são migrações expand-and-contract:
- Expandir: Adicionar novas colunas/tabelas sem remover as antigas. Tornar novas colunas nullable ou com defaults.
- Deploy: Novo código escreve tanto nas colunas antigas quanto nas novas. Lê das novas com fallback para as antigas.
- Migrar dados: Preencher novas colunas a partir dos dados antigos.
- Contrair: Uma vez verificado, fazer deploy do código que usa apenas as novas colunas. Então remover as colunas antigas.
Isso torna cada passo independentemente reversível.
Gerenciamento de Secrets
Nunca hardcode secrets. Nunca comite arquivos .env. Aqui está como eu lido com secrets no GitHub Actions:
GitHub Secrets
Para a maioria dos casos, os secrets nativos do GitHub são suficientes. Eles são criptografados, nunca expostos em logs e com escopo de repositórios ou organizações.
env:
DATABASE_URL: ${{ secrets.DATABASE_URL }}
API_KEY: ${{ secrets.API_KEY }}
Secrets com Escopo de Ambiente
Secrets diferentes para staging e produção:
deploy-staging:
environment: staging
# ${{ secrets.DATABASE_URL }} resolves to the staging value
deploy-production:
environment: production
# ${{ secrets.DATABASE_URL }} resolves to the production value
Gerenciadores de Secrets Externos
Para times maiores ou requisitos de compliance mais rígidos, use AWS Secrets Manager, Google Secret Manager ou HashiCorp Vault. A aplicação busca secrets em tempo de execução em vez de recebê-los como variáveis de ambiente.
import { SecretManagerServiceClient } from '@google-cloud/secret-manager';
const client = new SecretManagerServiceClient();
async function getSecret(name: string): Promise<string> {
const [version] = await client.accessSecretVersion({
name: `projects/my-project/secrets/${name}/versions/latest`,
});
return version.payload?.data?.toString() || '';
}
Monitorando Deploys
Um deploy não termina quando o código está no ar. Ele termina quando você confirmou que o código está funcionando.
Notificações de Deploy
Envie eventos de deploy para o Slack com contexto relevante:
- name: Notify Slack
if: always()
uses: slackapi/slack-github-action@v2
with:
webhook: ${{ secrets.SLACK_WEBHOOK }}
webhook-type: incoming-webhook
payload: |
{
"text": "${{ job.status == 'success' && 'Deployed' || 'Failed to deploy' }} `${{ github.sha }}` to production",
"blocks": [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*${{ job.status == 'success' && ':white_check_mark: Deployment Successful' || ':x: Deployment Failed' }}*\nCommit: `${{ github.sha }}`\nAuthor: ${{ github.actor }}\nMessage: ${{ github.event.head_commit.message }}"
}
}
]
}
Health Checks Pós-Deploy
Após cada deploy de produção, verifique se os endpoints críticos respondem corretamente:
- name: Verify production health
run: |
endpoints=("/" "/api/health" "/api/v1/status")
for endpoint in "${endpoints[@]}"; do
status=$(curl -s -o /dev/null -w "%{http_code}" "https://api.example.com$endpoint")
if [ "$status" != "200" ]; then
echo "FAILED: $endpoint returned $status"
exit 1
fi
echo "OK: $endpoint returned $status"
done
Um Exemplo Completo de Pipeline
Juntando tudo, aqui está um pipeline condensado mas completo para uma aplicação Node.js implantada no Cloud Run:
name: CI/CD Pipeline
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: ${{ github.event_name == 'pull_request' }}
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx prettier --check "src/**/*.{ts,tsx}"
- run: npx eslint src/ --max-warnings 0
- run: npx tsc --noEmit
test:
needs: validate
runs-on: ubuntu-latest
services:
postgres:
image: postgres:16
env: { POSTGRES_USER: test, POSTGRES_PASSWORD: test, POSTGRES_DB: testdb }
ports: ['5432:5432']
options: --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx vitest run --coverage
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
build-and-push:
needs: test
if: github.event_name == 'push'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: docker/setup-buildx-action@v3
- uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- uses: docker/build-push-action@v6
with:
context: .
push: true
tags: ghcr.io/${{ github.repository }}:${{ github.sha }}
cache-from: type=gha
cache-to: type=gha,mode=max
deploy:
needs: build-and-push
runs-on: ubuntu-latest
environment:
name: ${{ github.ref == 'refs/heads/main' && 'production' || 'staging' }}
steps:
- uses: google-github-actions/auth@v2
with:
credentials_json: ${{ secrets.GCP_SA_KEY }}
- uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-${{ github.ref == 'refs/heads/main' && 'prod' || 'staging' }}
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
O bloco concurrency merece destaque — ele cancela execuções em andamento para o mesmo branch em pull requests, para que enviar uma correção enquanto o CI ainda está rodando não enfileire dois pipelines.
O Que Eu Faria Diferente Começando do Zero
Se eu estivesse configurando um pipeline do zero hoje, começaria apenas com os estágios de validação e testes — sem automação de deploy. Publicaria manualmente (ou com um script de deploy simples) pelas primeiras semanas enquanto a base de código se estabiliza. Adicionaria automação de deploy quando o processo manual se tornasse o gargalo, não antes. Otimização prematura de pipeline é tão real quanto otimização prematura de código, e debugar um pipeline de deploy quebrado às 2 da manhã é significativamente pior do que executar ./deploy.sh manualmente.
Projetos Relacionados
RestoHub
Restaurantes param de perder 30% para o Uber Eats — ganham seu próprio sistema de pedidos, cardápio, site e programa de fidelidade em uma única plataforma. Experiência completa no estilo Uber Eats, mas o restaurante fica com cada centavo.
TakeCare
Agora uma enfermeira monitora 250 pacientes remotamente — substituindo ligações manuais e visitas domiciliares nos maiores hospitais de Quebec. Em operação no Jewish General, CHUM e Douglas Mental Health Institute.