Patterns d'architecture multi-tenant : au-delà des bases
Patterns avancés d'architecture multi-tenant pour les plateformes SaaS — des stratégies d'isolation des données à la personnalisation par tenant et au scaling.
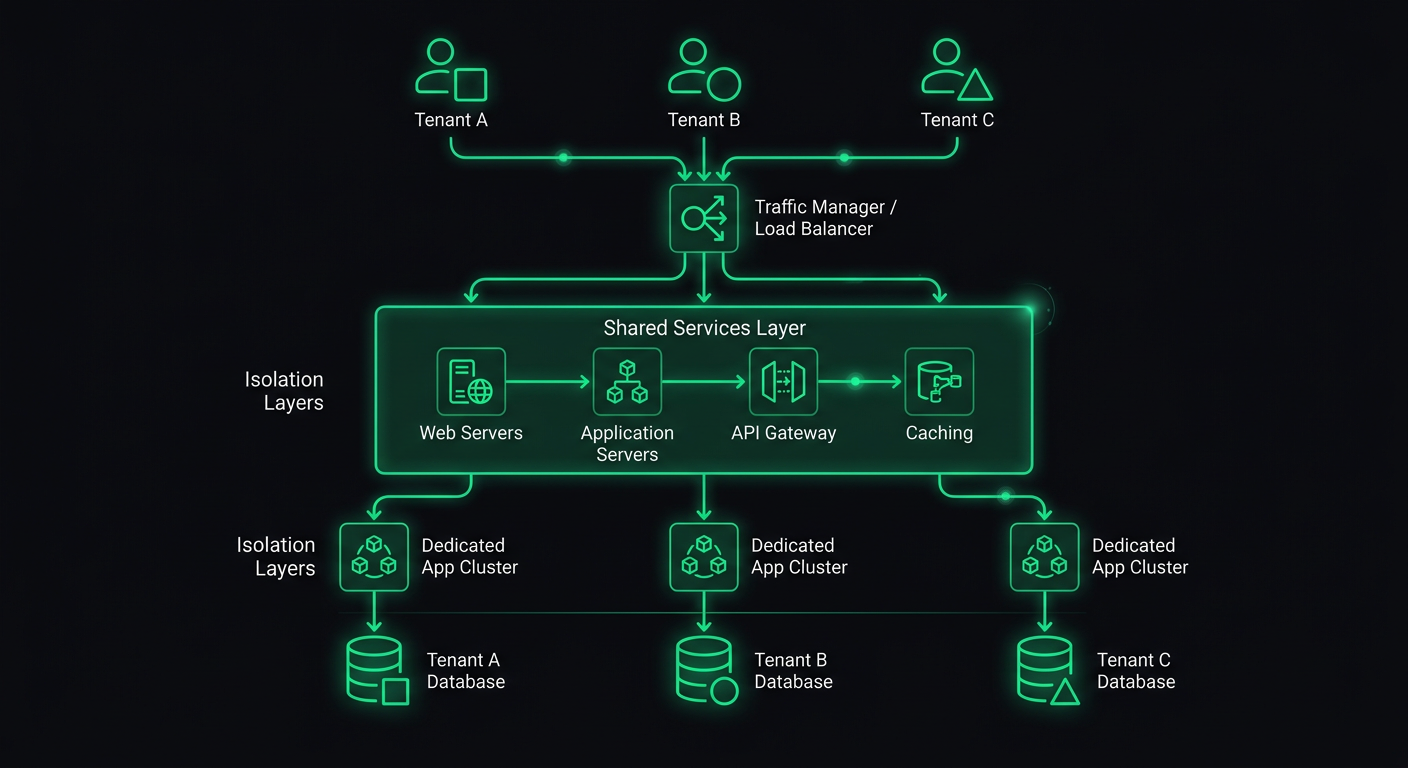
La plupart des guides sur le multi-tenancy s'arrêtent à "ajoutez une colonne tenant_id et filtrez vos requêtes." Cela vous porte pendant les premiers mois. Puis un tenant avec 10x plus de données commence à dégrader les performances pour tout le monde, un prospect enterprise demande du white-labeling, et un partenaire veut intégrer son propre processeur de paiement. Soudainement, les bases ne suffisent plus.
Cet article couvre les patterns que j'ai implémentés dans des systèmes multi-tenant en production qui vont au-delà du scoping de requêtes. Ce sont les décisions architecturales qui séparent un prototype d'une plateforme.
Patterns d'isolation avancés
Le modèle à trois niveaux — base de données partagée, schéma par tenant et base de données par tenant — est bien compris. Ce qui est moins discuté, c'est l'approche hybride que la plupart des systèmes en production finissent par utiliser.
Isolation par palier selon le segment client
En pratique, vous choisissez rarement un seul niveau d'isolation que vous appliquez uniformément. Au lieu de cela, vous échelonnez votre isolation en fonction de ce que chaque segment client a besoin et est prêt à payer.
interface TenantConfig {
id: string;
slug: string;
isolationLevel: "shared" | "schema" | "dedicated";
databaseUrl?: string; // only for dedicated tenants
schemaName?: string; // only for schema-isolated tenants
}
function getConnectionForTenant(tenant: TenantConfig) {
switch (tenant.isolationLevel) {
case "shared":
return getSharedPool();
case "schema":
return getSchemaConnection(tenant.schemaName!);
case "dedicated":
return getDedicatedConnection(tenant.databaseUrl!);
}
}
Le palier partagé sert vos clients en self-service. L'isolation par schéma sert les clients mid-market qui ont besoin de documentation de conformité. Les bases de données dédiées servent les comptes enterprise qui nécessitent une séparation physique des données.
La contrainte de conception clé : votre code applicatif ne devrait pas savoir ni se soucier du palier d'un tenant. La résolution de connexion se fait dans le middleware, et tout ce qui est en aval utilise la même interface de requête. Si un handler de route doit vérifier le niveau d'isolation pour décider comment requêter les données, votre abstraction fuit.
Row-Level Security comme filet de sécurité
La Row-Level Security de PostgreSQL est la fonctionnalité la plus sous-utilisée dans les architectures multi-tenant. Même avec un scoping de requêtes discipliné dans votre couche applicative, RLS fournit une garantie au niveau base de données qu'un tenant ne peut pas accéder aux données d'un autre.
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
CREATE POLICY tenant_isolation ON orders
USING (tenant_id = current_setting('app.current_tenant')::uuid);
ALTER TABLE orders FORCE ROW LEVEL SECURITY;
Au niveau connexion, vous définissez le contexte du tenant avant d'exécuter toute requête :
async function withTenantContext<T>(
tenantId: string,
callback: (client: PoolClient) => Promise<T>
): Promise<T> {
const client = await pool.connect();
try {
await client.query("SET app.current_tenant = $1", [tenantId]);
return await callback(client);
} finally {
await client.query("RESET app.current_tenant");
client.release();
}
}
Avec cela en place, même si votre code applicatif a un bug qui omet la clause WHERE tenant_id = ?, la base de données elle-même filtrera les résultats. Cela a attrapé de vrais bugs en production pour moi. Un développeur a écrit une requête de reporting qui faisait des jointures entre tables et a oublié le filtre tenant sur l'une d'entre elles — RLS a silencieusement retourné uniquement les bonnes lignes au lieu de fuiter des données.
Le FORCE ROW LEVEL SECURITY est important. Sans cela, les propriétaires de tables (typiquement le rôle utilisé par votre application) contournent les politiques RLS. Avec, les politiques s'appliquent à tout le monde.
Pipeline de middleware tenant-aware
Le middleware de résolution de tenant que j'ai couvert dans mon article précédent sur les backends multi-tenant gère les bases : extraire le tenant du sous-domaine ou du JWT, l'attacher à la requête. Mais un système en production a besoin d'un pipeline de middleware plus riche qui construit un contexte tenant complet.
interface TenantContext {
id: string;
slug: string;
config: TenantConfig;
plan: PlanTier;
features: Set<string>;
limits: TenantLimits;
branding?: TenantBranding;
}
async function buildTenantContext(tenantId: string): Promise<TenantContext> {
// Cache this aggressively — it's read on every request
const cacheKey = `tenant:${tenantId}:context`;
const cached = await redis.get(cacheKey);
if (cached) return JSON.parse(cached);
const [tenant, plan, features, limits, branding] = await Promise.all([
db("tenants").where({ id: tenantId }).first(),
db("tenant_plans").where({ tenant_id: tenantId, active: true }).first(),
db("tenant_features").where({ tenant_id: tenantId, enabled: true }).select("feature_key"),
db("tenant_limits").where({ tenant_id: tenantId }).first(),
db("tenant_branding").where({ tenant_id: tenantId }).first(),
]);
const context: TenantContext = {
id: tenant.id,
slug: tenant.slug,
config: tenant.config,
plan: plan.tier,
features: new Set(features.map((f) => f.feature_key)),
limits: limits ?? DEFAULT_LIMITS,
branding: branding ?? undefined,
};
await redis.set(cacheKey, JSON.stringify(context), "EX", 300);
return context;
}
Le middleware attache ensuite ce contexte complet à la requête :
export async function tenantContextMiddleware(
req: Request,
res: Response,
next: NextFunction
) {
if (!req.tenantId) return next();
try {
req.tenantContext = await buildTenantContext(req.tenantId);
// Check if tenant is active
if (req.tenantContext.config.status === "suspended") {
return res.status(403).json({
error: "Account suspended",
reason: req.tenantContext.config.suspensionReason,
});
}
next();
} catch (error) {
next(error);
}
}
Chaque handler en aval a maintenant accès au contexte tenant complet sans faire d'appels base de données supplémentaires. Le cache de cinq minutes signifie qu'un changement de plan se propage rapidement, mais vous ne sollicitez pas la base de données à chaque requête pour vérifier si une fonctionnalité est activée.
Configuration dynamique par tenant
Au-delà des feature flags, les tenants ont souvent besoin de comportements configurables. Une plateforme de restauration pourrait laisser chaque restaurant définir ses propres heures limites de commande, taux de taxes, zones de livraison et préférences de notification. Un outil de gestion de projet pourrait laisser chaque workspace configurer des champs personnalisés, des étapes de workflow et des règles de notification.
Le pattern que j'utilise sépare la configuration dans une colonne JSON validée par schéma :
import { z } from "zod";
const TenantSettingsSchema = z.object({
timezone: z.string().default("UTC"),
locale: z.string().default("en"),
currency: z.string().default("USD"),
notifications: z.object({
emailDigest: z.enum(["daily", "weekly", "never"]).default("daily"),
slackWebhook: z.string().url().optional(),
webhookUrl: z.string().url().optional(),
}).default({}),
limits: z.object({
maxUsersOverride: z.number().optional(),
maxStorageMbOverride: z.number().optional(),
apiRateLimitOverride: z.number().optional(),
}).default({}),
customFields: z.array(z.object({
key: z.string(),
label: z.string(),
type: z.enum(["text", "number", "date", "select"]),
options: z.array(z.string()).optional(),
required: z.boolean().default(false),
})).default([]),
});
type TenantSettings = z.infer<typeof TenantSettingsSchema>;
Les paramètres sont stockés en JSONB dans PostgreSQL, ce qui vous donne des capacités d'indexation et de requête tout en gardant le schéma flexible :
async function getTenantSettings(tenantId: string): Promise<TenantSettings> {
const row = await db("tenant_settings")
.where({ tenant_id: tenantId })
.first();
return TenantSettingsSchema.parse(row?.settings ?? {});
}
async function updateTenantSettings(
tenantId: string,
updates: Partial<TenantSettings>
): Promise<TenantSettings> {
const current = await getTenantSettings(tenantId);
const merged = { ...current, ...updates };
const validated = TenantSettingsSchema.parse(merged);
await db("tenant_settings")
.insert({
tenant_id: tenantId,
settings: validated,
updated_at: new Date(),
})
.onConflict("tenant_id")
.merge();
// Invalidate cache
await redis.del(`tenant:${tenantId}:context`);
return validated;
}
Le schéma Zod sert un double objectif : il valide les paramètres en écriture et fournit les valeurs par défaut en lecture. Si vous ajoutez un nouveau paramètre, les tenants existants obtiennent automatiquement la valeur par défaut sans migration de données.
Feature flags par tenant
Les simples flags booléens ne suffisent pas pour une plateforme mature. Vous avez besoin de support pour les déploiements par pourcentage, le gating basé sur le plan et les overrides par tenant.
interface FeatureFlag {
key: string;
defaultEnabled: boolean;
rolloutPercentage: number; // 0-100
planMinimum?: PlanTier;
tenantOverrides: Map<string, boolean>; // explicit per-tenant overrides
}
class FeatureFlagService {
private flags: Map<string, FeatureFlag>;
constructor(private cache: CacheStore) {
this.flags = new Map();
}
async isEnabled(tenantId: string, featureKey: string): Promise<boolean> {
const flag = await this.getFlag(featureKey);
if (!flag) return false;
// Explicit per-tenant override takes precedence
if (flag.tenantOverrides.has(tenantId)) {
return flag.tenantOverrides.get(tenantId)!;
}
// Plan-based gating
if (flag.planMinimum) {
const tenantPlan = await this.getTenantPlan(tenantId);
if (planRank(tenantPlan) < planRank(flag.planMinimum)) {
return false;
}
}
// Percentage rollout — deterministic based on tenant ID
if (flag.rolloutPercentage < 100) {
const hash = this.hashTenantFeature(tenantId, featureKey);
return hash % 100 < flag.rolloutPercentage;
}
return flag.defaultEnabled;
}
private hashTenantFeature(tenantId: string, featureKey: string): number {
const str = `${tenantId}:${featureKey}`;
let hash = 0;
for (let i = 0; i < str.length; i++) {
hash = ((hash << 5) - hash + str.charCodeAt(i)) | 0;
}
return Math.abs(hash);
}
}
Le hash déterministe est important pour les déploiements progressifs. Un tenant voit soit la fonctionnalité de manière cohérente, soit il ne la voit pas — vous ne voulez pas qu'il la voie sur une requête et pas sur la suivante. Le hash est calculé à partir de l'identifiant du tenant et de la clé de fonctionnalité, donc différentes fonctionnalités peuvent être déployées vers différents sous-ensembles de tenants.
Dans les handlers de route, la vérification est propre :
app.get("/api/v2/analytics", async (req, res) => {
const useNewAnalytics = await featureFlags.isEnabled(
req.tenantId,
"analytics_v2"
);
if (useNewAnalytics) {
return res.json(await analyticsV2.getDashboard(req.tenantId));
}
return res.json(await analyticsV1.getDashboard(req.tenantId));
});
Intégrations spécifiques par tenant
Les tenants enterprise voudront connecter leurs propres outils : leur propre compte Stripe pour le traitement des paiements, leur propre compte SendGrid pour les emails, leur propre bucket S3 pour le stockage de fichiers. Votre plateforme doit supporter cela sans devenir un cauchemar de configuration.
Le pattern est un registre d'intégrations qui résout les bons identifiants par tenant :
interface IntegrationConfig {
provider: string;
credentials: Record<string, string>; // encrypted at rest
settings: Record<string, unknown>;
isCustom: boolean; // true = tenant's own account, false = platform default
}
class IntegrationRegistry {
async getIntegration(
tenantId: string,
integrationType: "email" | "payment" | "storage" | "sms"
): Promise<IntegrationConfig> {
// Check for tenant-specific integration first
const custom = await db("tenant_integrations")
.where({ tenant_id: tenantId, type: integrationType, active: true })
.first();
if (custom) {
return {
provider: custom.provider,
credentials: await decrypt(custom.encrypted_credentials),
settings: custom.settings,
isCustom: true,
};
}
// Fall back to platform defaults
return this.getPlatformDefault(integrationType);
}
}
La couche service utilise ensuite le registre pour obtenir le bon client :
class EmailService {
constructor(private integrations: IntegrationRegistry) {}
async sendEmail(tenantId: string, email: EmailPayload): Promise<void> {
const config = await this.integrations.getIntegration(tenantId, "email");
const client = this.createClient(config);
await client.send({
from: config.settings.fromAddress as string,
...email,
});
}
private createClient(config: IntegrationConfig): EmailClient {
switch (config.provider) {
case "sendgrid":
return new SendGridClient(config.credentials.apiKey);
case "ses":
return new SESClient(config.credentials);
case "resend":
return new ResendClient(config.credentials.apiKey);
default:
throw new Error(`Unknown email provider: ${config.provider}`);
}
}
}
Cela signifie qu'un tenant peut utiliser le compte SendGrid partagé de la plateforme tandis qu'un autre utilise sa propre instance Amazon SES avec son propre domaine et sa propre réputation. Le reste de votre code applicatif ne sait pas et ne se soucie pas — il appelle emailService.sendEmail() et la couche d'intégration gère le routage.
La sécurité des identifiants est non négociable ici. Les clés API fournies par les tenants doivent être chiffrées au repos, de préférence avec des clés de chiffrement par tenant. Utilisez quelque chose comme AWS KMS ou HashiCorp Vault pour gérer cela — ne développez pas votre propre gestion de clés de chiffrement.
Migration de données entre niveaux d'isolation
L'un des défis opérationnels les plus délicats dans les systèmes multi-tenant est la migration d'un tenant d'un niveau d'isolation à un autre. Un tenant en croissance pourrait passer des tables partagées à son propre schéma. Un contrat enterprise pourrait nécessiter la migration d'un tenant vers une base de données dédiée.
La migration doit être sans interruption, ce qui signifie que vous ne pouvez pas simplement dump et restaurer. Voici le pattern que j'utilise :
interface TenantMigration {
tenantId: string;
fromLevel: IsolationLevel;
toLevel: IsolationLevel;
status: "pending" | "syncing" | "verifying" | "cutover" | "complete" | "failed";
startedAt: Date;
completedAt?: Date;
}
class TenantMigrator {
async migrateToSchema(tenantId: string): Promise<void> {
const migration = await this.createMigration(tenantId, "shared", "schema");
try {
// 1. Create the target schema with all tables
await this.createSchema(tenantId);
await this.updateStatus(migration, "syncing");
// 2. Copy existing data to the new schema
await this.copyData(tenantId, "public", `tenant_${tenantId}`);
// 3. Set up Change Data Capture to sync ongoing writes
const cdcStream = await this.startCDC(tenantId, "public", `tenant_${tenantId}`);
// 4. Verify data consistency
await this.updateStatus(migration, "verifying");
const isConsistent = await this.verifyConsistency(tenantId);
if (!isConsistent) throw new Error("Data consistency check failed");
// 5. Cutover: update tenant config to point to new schema
await this.updateStatus(migration, "cutover");
await db("tenants").where({ id: tenantId }).update({
isolation_level: "schema",
schema_name: `tenant_${tenantId}`,
});
// 6. Invalidate caches
await redis.del(`tenant:${tenantId}:context`);
// 7. Stop CDC and clean up source data
await cdcStream.stop();
await this.cleanupSourceData(tenantId, "public");
await this.updateStatus(migration, "complete");
} catch (error) {
await this.updateStatus(migration, "failed");
await this.rollback(migration);
throw error;
}
}
}
L'étape de Change Data Capture est critique. Entre la copie des données initiales et le basculement, de nouvelles écritures se produisent sur les tables partagées. Le CDC capture ces écritures et les rejoue dans le nouveau schéma pour que rien ne soit perdu.
En pratique, j'utilise la réplication logique de PostgreSQL pour cela. Vous créez une publication sur les tables sources filtrées par tenant_id, et un abonnement sur le schéma cible. Une fois que le retard de réplication est proche de zéro, vous effectuez le basculement.
Le chemin de rollback est tout aussi important. Si quelque chose échoue pendant la migration, vous devez pouvoir tout défaire proprement. Cela signifie garder les données sources intactes jusqu'à ce que la migration soit vérifiée et que le tenant ait opéré sur le nouveau schéma pendant une période de confiance (j'attends typiquement 48 heures avant de nettoyer les données sources).
Monitoring et observabilité par tenant
Dans un système multi-tenant, "l'API est lente" n'est pas actionnable. Vous devez savoir quel tenant est affecté, quelles requêtes sont lentes, et si le problème est spécifique au tenant (voisin bruyant, gros jeu de données) ou à l'échelle de la plateforme.
import { metrics } from "./lib/metrics"; // Prometheus, Datadog, etc.
function tenantMetricsMiddleware(req: Request, res: Response, next: NextFunction) {
const start = Date.now();
res.on("finish", () => {
const duration = Date.now() - start;
const labels = {
tenant_id: req.tenantId,
method: req.method,
route: req.route?.path ?? "unknown",
status: String(res.statusCode),
};
metrics.histogram("http_request_duration_ms", duration, labels);
metrics.counter("http_requests_total", 1, labels);
// Alert on tenant-specific degradation
if (duration > 2000) {
metrics.counter("http_slow_requests_total", 1, labels);
}
});
next();
}
Au-delà des métriques au niveau requête, suivez la consommation de ressources par tenant :
interface TenantUsageMetrics {
tenantId: string;
period: string; // "2026-03"
apiCalls: number;
storageBytes: number;
bandwidthBytes: number;
computeMs: number;
activeUsers: number;
}
class UsageTracker {
async recordAPICall(tenantId: string, durationMs: number): Promise<void> {
const period = this.getCurrentPeriod();
await redis.hincrby(`usage:${tenantId}:${period}`, "apiCalls", 1);
await redis.hincrby(`usage:${tenantId}:${period}`, "computeMs", durationMs);
}
async getUsage(tenantId: string, period: string): Promise<TenantUsageMetrics> {
const data = await redis.hgetall(`usage:${tenantId}:${period}`);
return {
tenantId,
period,
apiCalls: parseInt(data.apiCalls ?? "0"),
storageBytes: parseInt(data.storageBytes ?? "0"),
bandwidthBytes: parseInt(data.bandwidthBytes ?? "0"),
computeMs: parseInt(data.computeMs ?? "0"),
activeUsers: parseInt(data.activeUsers ?? "0"),
};
}
}
Ces données alimentent trois objectifs : la facturation (tarification basée sur l'usage), la planification de capacité (quels tenants croissent le plus vite) et le débogage (l'expérience lente de ce tenant est-elle due à leur volume de données ou à un problème de plateforme).
Configurez des tableaux de bord avec des ventilations par tenant. Quand une alerte se déclenche, vous devriez pouvoir voir en quelques secondes si elle affecte un seul tenant ou tous. Cela transforme votre réponse aux incidents de "quelque chose est lent" à "les requêtes analytics du Tenant X sont lentes parce que leur jeu de données a dépassé le seuil où nos index actuels sont efficaces."
Patterns d'intégration de facturation
La facturation dans un système multi-tenant va au-delà de "facturer chaque tenant mensuellement." Vous devez gérer les paliers de plans, les composants basés sur l'usage, la tarification par siège, et les upgrades et downgrades en cours de cycle.
class BillingService {
private stripe: Stripe;
async syncPlanChange(tenantId: string, newPlan: PlanTier): Promise<void> {
const tenant = await db("tenants").where({ id: tenantId }).first();
// Update Stripe subscription
const subscription = await this.stripe.subscriptions.retrieve(
tenant.stripe_subscription_id
);
await this.stripe.subscriptions.update(subscription.id, {
items: [{
id: subscription.items.data[0].id,
price: PLAN_PRICE_IDS[newPlan],
}],
proration_behavior: "create_prorations",
});
// Sync feature flags based on new plan
await this.syncFeatureFlags(tenantId, newPlan);
// Update limits
await this.syncLimits(tenantId, newPlan);
// Invalidate tenant context cache
await redis.del(`tenant:${tenantId}:context`);
}
private async syncFeatureFlags(tenantId: string, plan: PlanTier): Promise<void> {
const planFeatures = PLAN_FEATURE_MAP[plan];
// Disable features not included in new plan
await db("tenant_features")
.where({ tenant_id: tenantId })
.whereNotIn("feature_key", planFeatures)
.update({ enabled: false });
// Enable features included in new plan
for (const feature of planFeatures) {
await db("tenant_features")
.insert({ tenant_id: tenantId, feature_key: feature, enabled: true })
.onConflict(["tenant_id", "feature_key"])
.merge();
}
}
}
Pour la facturation basée sur l'usage, vous rapportez l'utilisation à Stripe à la fin de chaque période de facturation :
async function reportUsageToStripe(tenantId: string): Promise<void> {
const tenant = await db("tenants").where({ id: tenantId }).first();
const usage = await usageTracker.getUsage(tenantId, getCurrentPeriod());
// Report metered usage for API calls
await stripe.subscriptionItems.createUsageRecord(
tenant.stripe_metered_item_id,
{
quantity: usage.apiCalls,
timestamp: Math.floor(Date.now() / 1000),
action: "set",
}
);
}
Exécutez cela sur un cron job à la fin de chaque période de facturation, et implémentez l'idempotence pour que l'exécuter deux fois ne double pas la facturation.
Architecture de white-labeling
Le white-labeling est la capacité pour les tenants de présenter votre plateforme comme leur propre produit. Cela signifie des domaines personnalisés, un branding personnalisé, des templates d'email personnalisés, et parfois des thèmes UI personnalisés.
L'architecture a deux préoccupations principales : le routage et le theming.
Routage par domaine personnalisé
// Tenant domain mapping
interface TenantDomain {
tenantId: string;
domain: string; // "orders.acme-restaurant.com"
sslStatus: "pending" | "active" | "expired";
verifiedAt?: Date;
}
async function resolveCustomDomain(hostname: string): Promise<string | null> {
const mapping = await redis.get(`domain:${hostname}`);
if (mapping) return mapping;
const row = await db("tenant_domains")
.where({ domain: hostname, ssl_status: "active" })
.first();
if (row) {
await redis.set(`domain:${hostname}`, row.tenant_id, "EX", 3600);
return row.tenant_id;
}
return null;
}
Dans votre middleware de résolution de tenant, vérifiez les domaines personnalisés avant de se rabattre sur la résolution par sous-domaine :
export async function tenantMiddleware(req: Request, res: Response, next: NextFunction) {
// 1. Check JWT claim
// ... (existing logic)
// 2. Check custom domain
const customTenantId = await resolveCustomDomain(req.hostname);
if (customTenantId) {
req.tenantId = customTenantId;
return next();
}
// 3. Fall back to subdomain
// ... (existing logic)
}
Pour le SSL sur les domaines personnalisés, utilisez un certificat wildcard pour vos sous-domaines et Let's Encrypt avec challenge DNS ou HTTP pour les domaines personnalisés. Des services comme Caddy ou Cloudflare for SaaS peuvent automatiser cela entièrement.
Theming et branding
interface TenantBranding {
tenantId: string;
logoUrl: string;
faviconUrl: string;
primaryColor: string;
secondaryColor: string;
fontFamily?: string;
customCSS?: string;
emailFromName: string;
emailFromAddress: string;
supportUrl?: string;
termsUrl?: string;
privacyUrl?: string;
}
Côté frontend, injectez le branding comme propriétés CSS personnalisées :
function applyBranding(branding: TenantBranding) {
const root = document.documentElement;
root.style.setProperty("--color-primary", branding.primaryColor);
root.style.setProperty("--color-secondary", branding.secondaryColor);
if (branding.fontFamily) {
root.style.setProperty("--font-family", branding.fontFamily);
}
}
Si la plateforme est rendue côté serveur, injectez le branding dans la réponse HTML initiale pour éviter un flash de contenu non stylé. Avec Next.js, cela signifie lire le branding dans votre layout racine et définir les variables CSS en inline dans la balise <html> ou <body>.
Pour les templates d'email, utilisez le contexte de branding du tenant lors du rendu :
async function sendTenantEmail(tenantId: string, template: string, data: unknown) {
const branding = await getBranding(tenantId);
const integration = await integrations.getIntegration(tenantId, "email");
const html = renderEmailTemplate(template, {
...data,
logo: branding.logoUrl,
primaryColor: branding.primaryColor,
companyName: branding.emailFromName,
});
await emailClient(integration).send({
from: `${branding.emailFromName} <${branding.emailFromAddress}>`,
html,
});
}
L'utilisateur final ne voit jamais la marque de votre plateforme. Il voit le logo, les couleurs, le domaine et l'adresse d'expédition du tenant. Pour lui, c'est le produit du tenant.
Considérations de scaling
Au fur et à mesure que votre nombre de tenants croît, certains patterns cessent de fonctionner et doivent être remplacés.
Le pooling de connexions devient critique. Avec des bases de données partagées, vous pourriez commencer avec un pool de connexions par instance applicative. Mais quand vous avez un schéma par tenant ou une base par tenant, la gestion naïve des connexions épuisera vos limites de connexions. Utilisez PgBouncer en mode transaction pour les bases partagées, et implémentez un partitionnement du pool de connexions pour l'isolation par schéma où les connexions sont allouées proportionnellement à l'activité du tenant.
L'invalidation du cache devient plus difficile. Avec une seule instance Redis, supprimer le cache d'un tenant est simple. Avec un cache distribué, vous devez diffuser les événements d'invalidation. Utilisez Redis Pub/Sub ou un bus d'événements dédié pour propager les invalidations de cache à travers toutes les instances applicatives.
Les jobs en arrière-plan ont besoin du contexte tenant. Chaque job que vous mettez en file d'attente doit porter l'identifiant du tenant. Le processeur de jobs doit mettre en place le même contexte tenant (connexion base de données, feature flags, limites) que le middleware HTTP. Je crée un wrapper withTenantScope pour les handlers de jobs :
function withTenantScope(handler: (tenantId: string, data: unknown) => Promise<void>) {
return async (job: Job) => {
const { tenantId, ...data } = job.data;
const tenant = await buildTenantContext(tenantId);
// Set up database context
await withTenantContext(tenantId, async () => {
await handler(tenantId, data);
});
};
}
// Usage
queue.process("generate-report", withTenantScope(async (tenantId, data) => {
// This handler runs with full tenant context
const report = await generateReport(tenantId, data);
await storeReport(tenantId, report);
}));
La détection de voisin bruyant est essentielle pour l'infrastructure partagée. Suivez le temps d'exécution des requêtes, l'utilisation CPU et la mémoire par tenant. Quand la charge de travail d'un tenant commence à dégrader le pool partagé, vous avez trois options : le limiter, le migrer vers un palier d'isolation supérieur, ou optimiser ses requêtes spécifiques. Le monitoring vous donne les données pour prendre cette décision avant que les autres tenants soient affectés.
Assembler le tout
Une architecture multi-tenant en production n'est pas un pattern unique — c'est un empilement de décisions qui interagissent entre elles. La stratégie d'isolation affecte votre gestion des connexions. Les feature flags affectent la facturation. Le white-labeling affecte l'ensemble de votre pipeline de rendu frontend. Les intégrations personnalisées affectent votre gestion d'erreurs et votre monitoring.
La séquence que je recommande aux équipes qui construisent cela de zéro :
- Commencez avec tout partagé et des requêtes scopées par tenant. Trouvez d'abord votre product-market fit.
- Ajoutez les feature flags et le gating basé sur les plans dès que vous avez une page de tarification.
- Construisez le registre d'intégrations quand votre premier client enterprise le demande.
- Implémentez l'isolation par schéma quand une exigence de conformité l'exige.
- Ajoutez le white-labeling quand un partenaire veut revendre votre plateforme.
- Construisez l'outillage de migration quand vous devez déplacer un tenant entre les paliers.
Chaque couche s'appuie sur la précédente. Le pipeline de middleware, l'interface de requête scopée et le registre d'intégrations sont des fondations qui supportent tout ce qui est au-dessus. Faites-les bien, et les patterns avancés se mettent en place naturellement.
J'ai construit ces patterns à travers des plateformes de restauration, du SaaS médical et des outils de gestion de projet. Les domaines sont différents, mais les défis du multi-tenancy sont remarquablement constants. L'investissement dans une isolation, une configuration et une observabilité appropriées des tenants se rentabilise au moment où vous signez votre premier client enterprise qui demande : "Comment mes données sont-elles séparées de celles de vos autres clients ?"
Cette question est un signal d'achat. L'architecture que vous avez construite est la réponse.
Danil Ulmashev
Full Stack Developer
Intéressé par une collaboration ?