Configuration de pipeline CI/CD qui fonctionne vraiment en production
Des patterns CI/CD éprouvés au combat pour de vrais projets — des workflows GitHub Actions aux stratégies de déploiement qui ne cassent pas la production un vendredi.
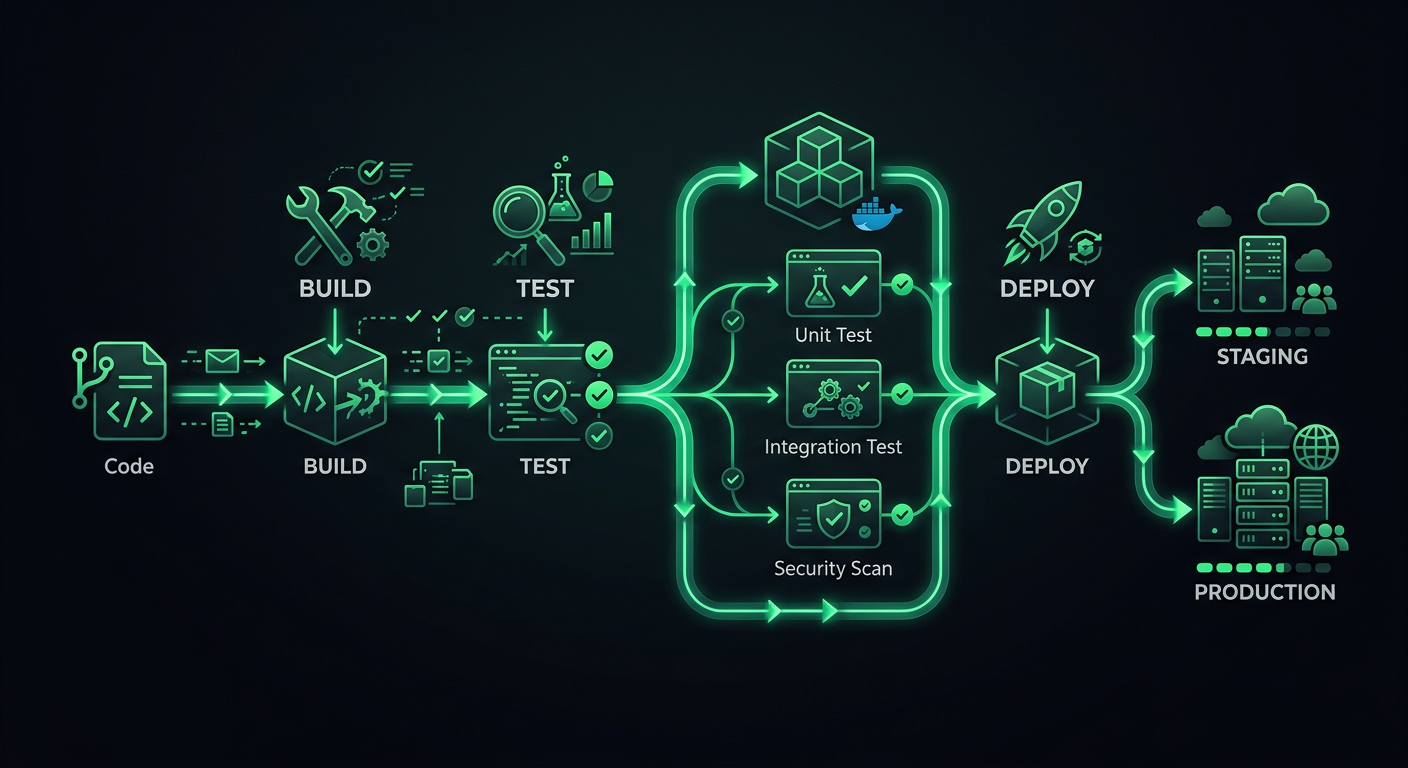
Le premier pipeline CI/CD que j'ai mis en place pour un projet de production était un simple workflow GitHub Actions qui exécutait npm test puis déployait sur un VPS via SSH. Ça fonctionnait jusqu'à ce que ça ne fonctionne plus — un déploiement échoué a laissé le serveur dans un état à moitié mis à jour un vendredi soir, et j'ai passé le weekend à reverter manuellement les fichiers. Cette expérience m'a appris qu'un pipeline de déploiement n'est pas juste "exécuter les tests puis déployer". C'est l'ensemble du système de vérifications, de portes et de mécanismes de rollback qui se trouve entre un git push et le moment où vos utilisateurs voient le nouveau code.
Cet article couvre l'architecture de pipeline que j'ai affinée sur plusieurs projets de production, avec des exemples concrets GitHub Actions que vous pouvez adapter.
Architecture du pipeline
Un pipeline de production a des étapes distinctes, et chaque étape a un objectif spécifique. Sauter des étapes fait gagner des minutes maintenant et coûte des heures plus tard.
Les étapes
Code Push
│
├─→ Étape 1 : Validation (lint, format, type-check)
│
├─→ Étape 2 : Tests (unitaires, intégration)
│
├─→ Étape 3 : Build (compiler, bundler, containeriser)
│
├─→ Étape 4 : Déploiement en staging
│
├─→ Étape 5 : Smoke Tests / E2E sur staging
│
└─→ Étape 6 : Déploiement en production
Chaque étape agit comme une porte. Si la validation échoue, les tests ne s'exécutent jamais. Si les tests échouent, le build ne démarre jamais. Cela économise du temps de calcul et fournit un feedback rapide — les développeurs savent en 30 secondes s'ils ont oublié de lancer le linter, plutôt que d'attendre 8 minutes qu'une suite de tests échoue.
Stratégie de déclenchement
Chaque push n'a pas besoin du pipeline complet. Voici la configuration de déclenchement que j'utilise :
# .github/workflows/ci.yml
name: CI
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
types: [opened, synchronize, reopened]
Les pull requests exécutent les étapes 1-3 (validation, tests, build). Les merges vers develop déploient en staging. Les merges vers main déploient en production. Cela garde le feedback sur les PR rapide tout en garantissant que les déploiements ne se font qu'à partir de branches protégées.
Étape 1 : Validation
La validation attrape les incohérences de formatage et les erreurs de typage avant l'exécution des tests. Ces vérifications sont rapides (moins de 30 secondes) et attrapent les problèmes les plus courants.
jobs:
validate:
name: Validate
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Check formatting
run: npx prettier --check "src/**/*.{ts,tsx,js,jsx,json,css}"
- name: Lint
run: npx eslint src/ --max-warnings 0
- name: Type check
run: npx tsc --noEmit
La règle --max-warnings 0
ESLint distingue les erreurs (qui font échouer le processus) des avertissements (qui ne le font pas). Sans --max-warnings 0, les équipes accumulent des centaines d'avertissements que tout le monde ignore. Traiter les avertissements comme des erreurs en CI force l'équipe soit à les corriger, soit à désactiver explicitement la règle. Pas de juste milieu.
Le formatage comme vérification CI, pas juste une suggestion
Exécuter Prettier en CI (avec --check, pas --write) garantit un formatage cohérent sans dépendre du fait que chaque développeur ait la bonne extension d'éditeur. Si le formatage échoue en CI, le développeur exécute npx prettier --write . localement et commit le correctif. C'est non négociable — les débats sur le formatage cessent quand un outil prend les décisions.
Étape 2 : Tests
Les tests sont l'épine dorsale du pipeline. Je sépare les tests en jobs parallèles par type pour un feedback plus rapide.
unit-tests:
name: Unit Tests
runs-on: ubuntu-latest
needs: validate
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run unit tests
run: npx vitest run --coverage --reporter=verbose
- name: Upload coverage report
if: always()
uses: actions/upload-artifact@v4
with:
name: coverage-report
path: coverage/
integration-tests:
name: Integration Tests
runs-on: ubuntu-latest
needs: validate
services:
postgres:
image: postgres:16
env:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
POSTGRES_DB: testdb
ports:
- 5432:5432
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
redis:
image: redis:7
ports:
- 6379:6379
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run database migrations
run: npx prisma migrate deploy
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
- name: Run integration tests
run: npx vitest run --config vitest.integration.config.ts
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
REDIS_URL: redis://localhost:6379
Conteneurs de services pour les tests d'intégration
Les conteneurs de services GitHub Actions sont sous-utilisés. Au lieu de mocker votre base de données dans les tests d'intégration (ce qui teste le mock, pas votre code), lancez une vraie instance PostgreSQL. Le bloc services gère le cycle de vie — le conteneur démarre avant vos tests et s'arrête après.
Cela ajoute environ 15-20 secondes au job pour le démarrage du conteneur, mais la confiance que vous gagnez en testant contre une vraie base de données en vaut la peine.
Exécution parallèle des tests
Les tests unitaires et les tests d'intégration s'exécutent en parallèle (les deux ont needs: validate, pas needs: unit-tests). Cela réduit le temps total du pipeline. Si vos tests unitaires prennent 2 minutes et les tests d'intégration 4 minutes, l'exécution parallèle signifie que vous attendez 4 minutes au lieu de 6.
Étape 3 : Build
L'étape de build valide que le projet compile et produit des artefacts déployables.
build:
name: Build
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Build application
run: npm run build
env:
NODE_ENV: production
- name: Upload build artifacts
uses: actions/upload-artifact@v4
with:
name: build-output
path: dist/
retention-days: 7
Cache de build
Pour les déploiements basés sur Docker, le cache de couches accélère considérablement les builds :
build-docker:
name: Build Docker Image
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to Container Registry
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v6
with:
context: .
push: ${{ github.event_name != 'pull_request' }}
tags: |
ghcr.io/${{ github.repository }}:${{ github.sha }}
ghcr.io/${{ github.repository }}:latest
cache-from: type=gha
cache-to: type=gha,mode=max
Le cache-from: type=gha utilise le cache GitHub Actions pour stocker les couches Docker entre les exécutions. Pour une application Node.js typique, cela réduit le temps de build de 3-4 minutes à 30-60 secondes pour les changements de dépendances uniquement.
Bonnes pratiques Dockerfile pour le CI
La structure du Dockerfile impacte directement l'efficacité du cache de build. Ordonnez les couches des moins fréquemment modifiées aux plus fréquemment modifiées :
FROM node:20-alpine AS base
# System dependencies (rarely changes)
RUN apk add --no-cache libc6-compat
# Package manifests (changes when dependencies change)
WORKDIR /app
COPY package.json package-lock.json ./
# Install dependencies (cached unless manifests change)
FROM base AS deps
RUN npm ci --production
FROM base AS build
RUN npm ci
COPY . .
RUN npm run build
# Production image
FROM node:20-alpine AS runner
WORKDIR /app
ENV NODE_ENV=production
COPY --from=deps /app/node_modules ./node_modules
COPY --from=build /app/dist ./dist
COPY --from=build /app/package.json ./
EXPOSE 3000
CMD ["node", "dist/server.js"]
Les builds multi-étapes gardent l'image finale petite (pas de dépendances de développement, pas de code source), et l'ordonnancement des couches assure que npm ci ne s'exécute que quand package.json ou package-lock.json change.
Étapes 4-6 : Déploiement et stratégies
Les étapes de déploiement staging et production suivent le même principe : déployer automatiquement en staging sur les merges vers develop, avec des smoke tests avant de promouvoir en production.
Stratégie de déploiement Blue-Green
Deux environnements identiques (blue et green) existent. L'un sert le trafic tandis que l'autre est inactif. Déployez sur l'environnement inactif, vérifiez que ça fonctionne, puis basculez le routeur. Si quelque chose va mal, rebasculez.
deploy-production:
name: Deploy to Production
runs-on: ubuntu-latest
needs: smoke-tests
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
environment:
name: production
url: https://api.example.com
steps:
- name: Deploy new revision
uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-production
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
flags: '--no-traffic'
- name: Run production health check
run: |
REVISION_URL=$(gcloud run revisions describe my-api-production-${{ github.sha }} \
--region us-central1 --format='value(status.url)')
status=$(curl -s -o /dev/null -w "%{http_code}" "$REVISION_URL/health")
if [ "$status" != "200" ]; then
echo "Health check failed"
exit 1
fi
- name: Migrate traffic
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
Le flag --no-traffic déploie la nouvelle révision sans lui envoyer de trafic. Après que le health check passe, le trafic est basculé vers la nouvelle révision. Si le health check échoue, le workflow s'arrête et l'ancienne révision continue de servir.
Mécanismes de rollback
Chaque déploiement doit avoir un chemin de rollback documenté. "Re-déployer l'ancienne version" est une stratégie de rollback, mais c'est lent. De meilleures options :
Rollback instantané via bascule de trafic
# Roll back to the previous revision
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=PREVIOUS_REVISION=100
Cela prend effet en secondes car l'ancienne révision est toujours en cours d'exécution.
Rollback de migrations de base de données
C'est la partie la plus difficile. Si votre déploiement inclut des changements de schéma de base de données, faire un rollback de l'application sans faire un rollback de la base de données crée un décalage. La solution est les migrations expand-and-contract :
- Expand : Ajoutez de nouvelles colonnes/tables sans supprimer les anciennes. Rendez les nouvelles colonnes nullables ou avec des valeurs par défaut.
- Deploy : Le nouveau code écrit dans les anciennes et nouvelles colonnes. Lit depuis les nouvelles colonnes avec fallback sur les anciennes.
- Migrer les données : Remplissez les nouvelles colonnes à partir des anciennes données.
- Contract : Une fois vérifié, déployez le code qui n'utilise que les nouvelles colonnes. Puis supprimez les anciennes colonnes.
Cela rend chaque étape indépendamment réversible.
Gestion des secrets
Ne codez jamais les secrets en dur. Ne committez jamais de fichiers .env. Pour la plupart des cas, les secrets intégrés de GitHub sont suffisants. Ils sont chiffrés, jamais exposés dans les logs, et scopés aux dépôts ou organisations.
Pour différents secrets entre staging et production, utilisez les environnements GitHub :
deploy-staging:
environment: staging
# ${{ secrets.DATABASE_URL }} resolves to the staging value
deploy-production:
environment: production
# ${{ secrets.DATABASE_URL }} resolves to the production value
Un exemple de pipeline complet
Voici un pipeline condensé mais complet pour une application Node.js déployée sur Cloud Run :
name: CI/CD Pipeline
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: ${{ github.event_name == 'pull_request' }}
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx prettier --check "src/**/*.{ts,tsx}"
- run: npx eslint src/ --max-warnings 0
- run: npx tsc --noEmit
test:
needs: validate
runs-on: ubuntu-latest
services:
postgres:
image: postgres:16
env: { POSTGRES_USER: test, POSTGRES_PASSWORD: test, POSTGRES_DB: testdb }
ports: ['5432:5432']
options: --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx vitest run --coverage
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
build-and-push:
needs: test
if: github.event_name == 'push'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: docker/setup-buildx-action@v3
- uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- uses: docker/build-push-action@v6
with:
context: .
push: true
tags: ghcr.io/${{ github.repository }}:${{ github.sha }}
cache-from: type=gha
cache-to: type=gha,mode=max
deploy:
needs: build-and-push
runs-on: ubuntu-latest
environment:
name: ${{ github.ref == 'refs/heads/main' && 'production' || 'staging' }}
steps:
- uses: google-github-actions/auth@v2
with:
credentials_json: ${{ secrets.GCP_SA_KEY }}
- uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-${{ github.ref == 'refs/heads/main' && 'prod' || 'staging' }}
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
Le bloc concurrency mérite d'être noté — il annule les exécutions en cours pour la même branche sur les pull requests, de sorte que pousser un correctif pendant que le CI tourne ne met pas en file d'attente deux pipelines.
Ce que je ferais différemment en repartant de zéro
Si je mettais en place un pipeline à partir de zéro aujourd'hui, je commencerais uniquement avec les étapes de validation et de tests — pas d'automatisation de déploiement. Livrez manuellement (ou avec un simple script de déploiement) pendant les premières semaines pendant que la codebase se stabilise. Ajoutez l'automatisation du déploiement une fois que le processus manuel devient le goulot d'étranglement, pas avant. L'optimisation prématurée du pipeline est tout aussi réelle que l'optimisation prématurée du code, et déboguer un pipeline de déploiement cassé à 2h du matin est significativement pire que d'exécuter ./deploy.sh à la main.
Projets Associés
RestoHub
Les restaurants cessent de perdre 30 % au profit d'Uber Eats — ils obtiennent leur propre système de commande, menu, site web et programme de fidélité sur une seule plateforme. Une expérience comparable à Uber Eats, mais le restaurant garde chaque dollar.
TakeCare
Un seul infirmier surveille désormais 250 patients à distance — remplaçant les appels téléphoniques manuels et les visites à domicile dans les plus grands hôpitaux du Québec. En production au Jewish General, au CHUM et à l'Institut universitaire en santé mentale Douglas.
Danil Ulmashev
Full Stack Developer
Intéressé par une collaboration ?