Configuración de pipelines CI/CD que realmente funciona en producción
Patrones de CI/CD probados en batalla para proyectos reales — desde workflows de GitHub Actions hasta estrategias de despliegue que no rompen producción un viernes.
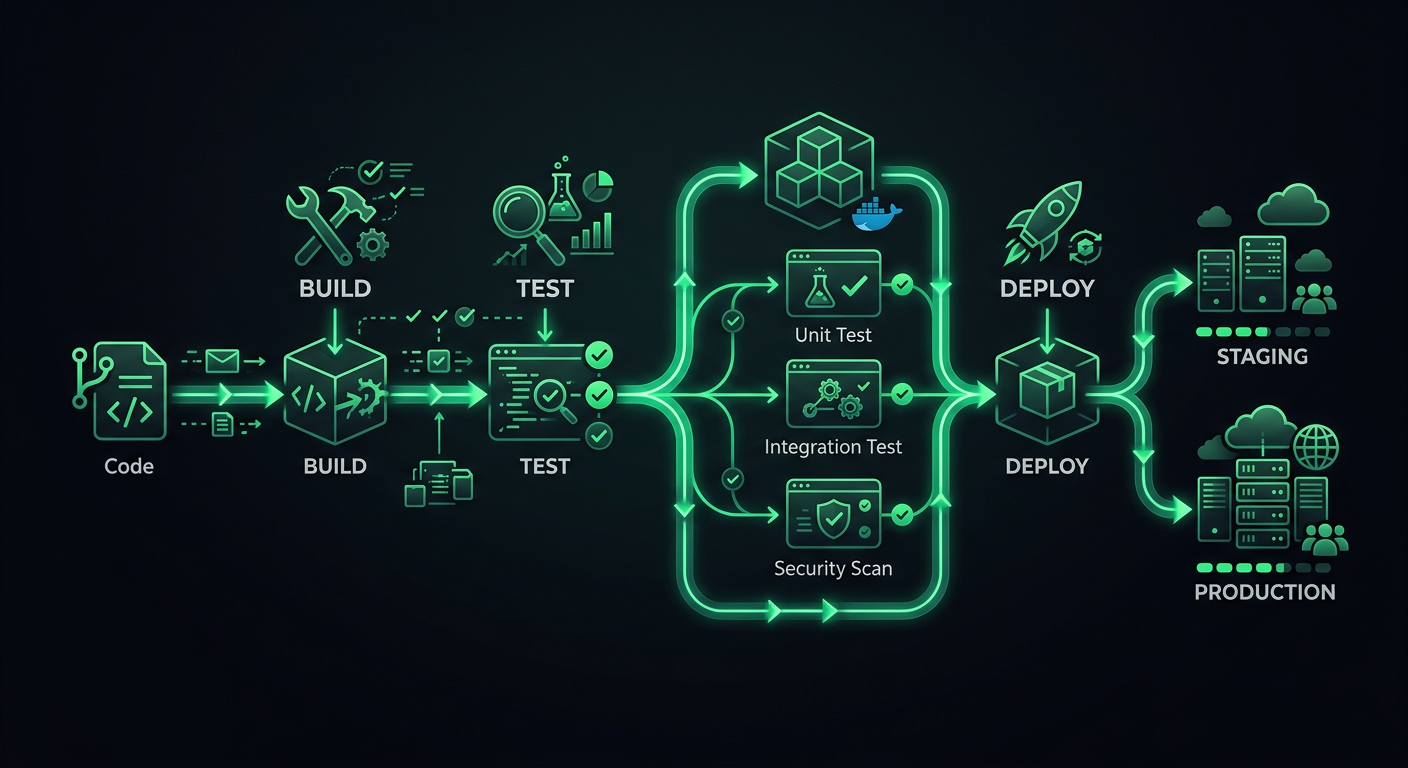
El primer pipeline de CI/CD que configuré para un proyecto en producción era un único workflow de GitHub Actions que ejecutaba npm test y luego desplegaba a un VPS vía SSH. Funcionó hasta que dejó de funcionar — un despliegue fallido dejó el servidor en un estado a medio actualizar un viernes por la noche, y pasé el fin de semana revirtiendo archivos manualmente. Esa experiencia me enseñó que un pipeline de despliegue no es solo "ejecutar tests y luego desplegar." Es todo el sistema de verificaciones, compuertas y mecanismos de rollback que se interponen entre un git push y tus usuarios viendo código nuevo.
Este artículo cubre la arquitectura de pipeline que he refinado a través de múltiples proyectos en producción, con ejemplos concretos de GitHub Actions que puedes adaptar.
Arquitectura del pipeline
Un pipeline de producción tiene etapas distintas, y cada etapa tiene un propósito específico. Saltarse etapas ahorra minutos ahora y cuesta horas después.
Las etapas
Code Push
│
├─→ Stage 1: Validation (lint, format, type-check)
│
├─→ Stage 2: Testing (unit, integration)
│
├─→ Stage 3: Build (compile, bundle, containerize)
│
├─→ Stage 4: Deploy to Staging
│
├─→ Stage 5: Smoke Tests / E2E on Staging
│
└─→ Stage 6: Deploy to Production
Cada etapa actúa como una compuerta. Si la validación falla, los tests nunca se ejecutan. Si los tests fallan, el build nunca comienza. Esto ahorra tiempo de cómputo y proporciona retroalimentación rápida — los desarrolladores saben en 30 segundos si olvidaron ejecutar el linter, en lugar de esperar 8 minutos a que el suite de tests falle.
Estrategia de triggers
No todo push necesita el pipeline completo. Aquí está la configuración de triggers que uso:
# .github/workflows/ci.yml
name: CI
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
types: [opened, synchronize, reopened]
Los pull requests ejecutan las etapas 1-3 (validar, testear, compilar). Los merges a develop despliegan a staging. Los merges a main despliegan a producción. Esto mantiene la retroalimentación de PRs rápida mientras asegura que los despliegues solo ocurran desde ramas protegidas.
Etapa 1: Validación
La validación detecta inconsistencias de formato y errores de tipos antes de que se ejecuten los tests. Estas verificaciones son rápidas (menos de 30 segundos) y detectan los problemas más comunes.
jobs:
validate:
name: Validate
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Check formatting
run: npx prettier --check "src/**/*.{ts,tsx,js,jsx,json,css}"
- name: Lint
run: npx eslint src/ --max-warnings 0
- name: Type check
run: npx tsc --noEmit
La regla --max-warnings 0
ESLint distingue entre errores (que fallan el proceso) y warnings (que no). Sin --max-warnings 0, los equipos acumulan cientos de warnings que todos ignoran. Tratar warnings como errores en CI obliga al equipo a corregirlos o desactivar explícitamente la regla. Sin término medio.
Formateo como verificación de CI, no solo como sugerencia
Ejecutar Prettier en CI (con --check, no --write) asegura un formato consistente sin depender de que cada desarrollador tenga la extensión de editor correcta. Si el formateo falla en CI, el desarrollador ejecuta npx prettier --write . localmente y hace commit de la corrección. Esto es innegociable — los debates de formato terminan cuando una herramienta toma las decisiones.
Etapa 2: Testing
El testing es la columna vertebral del pipeline. Divido los tests en jobs paralelos según el tipo para retroalimentación más rápida.
unit-tests:
name: Unit Tests
runs-on: ubuntu-latest
needs: validate
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run unit tests
run: npx vitest run --coverage --reporter=verbose
- name: Upload coverage report
if: always()
uses: actions/upload-artifact@v4
with:
name: coverage-report
path: coverage/
integration-tests:
name: Integration Tests
runs-on: ubuntu-latest
needs: validate
services:
postgres:
image: postgres:16
env:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
POSTGRES_DB: testdb
ports:
- 5432:5432
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
redis:
image: redis:7
ports:
- 6379:6379
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run database migrations
run: npx prisma migrate deploy
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
- name: Run integration tests
run: npx vitest run --config vitest.integration.config.ts
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
REDIS_URL: redis://localhost:6379
Contenedores de servicio para tests de integración
Los contenedores de servicio de GitHub Actions están subutilizados. En lugar de mockear tu base de datos en tests de integración (lo cual testea el mock, no tu código), levanta una instancia real de PostgreSQL. El bloque services maneja la gestión del ciclo de vida — el contenedor se inicia antes de tus tests y se detiene después.
Esto agrega unos 15-20 segundos al job por el inicio del contenedor, pero la confianza que obtienes al testear contra una base de datos real lo vale.
Ejecución paralela de tests
Los tests unitarios y de integración se ejecutan en paralelo (ambos needs: validate, no needs: unit-tests). Esto reduce el tiempo total del pipeline. Si tus tests unitarios toman 2 minutos y los de integración 4 minutos, la ejecución paralela significa que esperas 4 minutos en lugar de 6.
Etapa 3: Build
La etapa de build valida que el proyecto compila y produce artefactos desplegables.
build:
name: Build
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Build application
run: npm run build
env:
NODE_ENV: production
- name: Upload build artifacts
uses: actions/upload-artifact@v4
with:
name: build-output
path: dist/
retention-days: 7
Caché de build
Para despliegues basados en Docker, el caché de capas acelera dramáticamente los builds:
build-docker:
name: Build Docker Image
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to Container Registry
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v6
with:
context: .
push: ${{ github.event_name != 'pull_request' }}
tags: |
ghcr.io/${{ github.repository }}:${{ github.sha }}
ghcr.io/${{ github.repository }}:latest
cache-from: type=gha
cache-to: type=gha,mode=max
El cache-from: type=gha usa el caché de GitHub Actions para almacenar capas de Docker entre ejecuciones. Para una aplicación típica de Node.js, esto reduce el tiempo de build de 3-4 minutos a 30-60 segundos para cambios solo de dependencias.
Mejores prácticas de Dockerfile para CI
La estructura del Dockerfile impacta directamente la eficiencia del caché de build. Ordena las capas de lo que cambia con menor frecuencia a lo que cambia con mayor frecuencia:
FROM node:20-alpine AS base
# System dependencies (rarely changes)
RUN apk add --no-cache libc6-compat
# Package manifests (changes when dependencies change)
WORKDIR /app
COPY package.json package-lock.json ./
# Install dependencies (cached unless manifests change)
FROM base AS deps
RUN npm ci --production
FROM base AS build
RUN npm ci
COPY . .
RUN npm run build
# Production image
FROM node:20-alpine AS runner
WORKDIR /app
ENV NODE_ENV=production
COPY --from=deps /app/node_modules ./node_modules
COPY --from=build /app/dist ./dist
COPY --from=build /app/package.json ./
EXPOSE 3000
CMD ["node", "dist/server.js"]
Los builds multi-stage mantienen la imagen final pequeña (sin dependencias de desarrollo, sin código fuente), y el orden de capas asegura que npm ci solo se ejecute cuando package.json o package-lock.json cambien.
Etapa 4: Despliegue a staging
El despliegue a staging ocurre automáticamente en merges a la rama develop. El entorno de staging debería replicar producción lo más fielmente posible — misma infraestructura, mismas variables de entorno (con valores diferentes), misma configuración de escalado.
deploy-staging:
name: Deploy to Staging
runs-on: ubuntu-latest
needs: build
if: github.ref == 'refs/heads/develop' && github.event_name == 'push'
environment:
name: staging
url: https://staging.example.com
steps:
- uses: actions/checkout@v4
- name: Download build artifacts
uses: actions/download-artifact@v4
with:
name: build-output
path: dist/
- name: Deploy to Cloud Run (Staging)
uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-staging
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
env_vars: |
NODE_ENV=staging
DATABASE_URL=${{ secrets.STAGING_DATABASE_URL }}
Entornos de GitHub
La clave environment en el workflow habilita las reglas de protección de entornos de GitHub. Puedes requerir aprobación manual, restringir qué ramas pueden desplegar y establecer secrets específicos por entorno. Para staging, típicamente no requiero aprobación (auto-deploy). Para producción, requiero al menos un revisor.
Etapa 5: Smoke tests
Después de desplegar a staging, ejecuta un conjunto básico de tests contra la aplicación desplegada para verificar que realmente funciona en el entorno real.
smoke-tests:
name: Smoke Tests
runs-on: ubuntu-latest
needs: deploy-staging
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Wait for deployment
run: |
for i in {1..30}; do
status=$(curl -s -o /dev/null -w "%{http_code}" https://staging.example.com/health)
if [ "$status" = "200" ]; then
echo "Service is healthy"
exit 0
fi
echo "Waiting for service... (attempt $i)"
sleep 10
done
echo "Service did not become healthy"
exit 1
- name: Run smoke tests
run: npx playwright test --config=playwright.smoke.config.ts
env:
BASE_URL: https://staging.example.com
Los smoke tests no son tests E2E completos. Verifican rutas críticas: puede cargar la página principal, puede un usuario iniciar sesión, el endpoint principal de la API devuelve datos. Cinco a diez escenarios que toman menos de 2 minutos. Si los smoke tests fallan, el despliegue a staging se revierte y el despliegue a producción no procede.
Etapa 6: Despliegue a producción
El despliegue a producción es donde la estrategia de despliegue más importa. Hay varios enfoques, cada uno con diferentes trade-offs.
Despliegue rolling
La estrategia más simple. Las nuevas instancias se levantan mientras las antiguas se drenan. En cualquier punto durante el despliegue, algunas solicitudes llegan a la versión antigua y otras a la nueva. Este es el comportamiento por defecto en la mayoría de las plataformas de contenedores.
Pros: Simple, sin costo extra de infraestructura. Contras: Dos versiones sirven tráfico simultáneamente, lo cual puede causar problemas con cambios de esquema de base de datos o cambios de contrato de API.
Despliegue blue-green
Dos entornos idénticos (blue y green) existen. Uno sirve tráfico mientras el otro está inactivo. Despliegas al entorno inactivo, verificas que funciona, luego cambias el router. Si algo sale mal, cambias de vuelta.
deploy-production:
name: Deploy to Production
runs-on: ubuntu-latest
needs: smoke-tests
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
environment:
name: production
url: https://api.example.com
steps:
- name: Deploy new revision
uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-production
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
flags: '--no-traffic'
- name: Run production health check
run: |
REVISION_URL=$(gcloud run revisions describe my-api-production-${{ github.sha }} \
--region us-central1 --format='value(status.url)')
status=$(curl -s -o /dev/null -w "%{http_code}" "$REVISION_URL/health")
if [ "$status" != "200" ]; then
echo "Health check failed"
exit 1
fi
- name: Migrate traffic
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
La bandera --no-traffic despliega la nueva revisión sin enviarle tráfico. Después de que el health check pasa, el tráfico se redirige a la nueva revisión. Si el health check falla, el workflow se detiene y la revisión antigua continúa sirviendo.
Despliegue canary
Enruta un pequeño porcentaje de tráfico (5-10%) a la nueva versión mientras monitoreas tasas de error, latencia y métricas de negocio clave. Si las métricas se ven bien después de un período definido, incrementa gradualmente el tráfico. Si las métricas se degradan, revierte.
- name: Canary - route 10% of traffic
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=my-api-production-${{ github.sha }}=10
- name: Monitor canary (5 minutes)
run: |
sleep 300
# Check error rate for the canary revision
ERROR_RATE=$(curl -s "$MONITORING_API/error-rate?revision=${{ github.sha }}")
if (( $(echo "$ERROR_RATE > 1.0" | bc -l) )); then
echo "Error rate too high: $ERROR_RATE%. Rolling back."
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
exit 1
fi
- name: Promote canary to 100%
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
Cuándo usar canary: Cuando tienes suficiente tráfico para que el 10% genere tasas de error estadísticamente significativas. Para un servicio que maneja 100 solicitudes/minuto, el 10% te da 10 solicitudes/minuto — suficiente para detectar tasas de error elevadas en pocos minutos. Para un servicio que maneja 10 solicitudes/minuto, los despliegues canary no son significativos.
Mecanismos de rollback
Todo despliegue debe tener una ruta de rollback documentada. "Re-desplegar la versión anterior" es una estrategia de rollback, pero es lenta. Mejores opciones:
Rollback instantáneo vía cambio de tráfico
Si despliegas con --no-traffic y cambias tráfico, el rollback es un solo comando:
# Roll back to the previous revision
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=PREVIOUS_REVISION=100
Esto toma efecto en segundos porque la revisión antigua sigue ejecutándose.
Rollback automatizado
Agrega un paso de monitoreo post-despliegue que automáticamente revierte si las tasas de error se disparan:
- name: Post-deploy monitor
run: |
for i in {1..10}; do
sleep 60
ERROR_RATE=$(curl -s "$MONITORING_API/error-rate?window=5m")
if (( $(echo "$ERROR_RATE > 2.0" | bc -l) )); then
echo "Error rate $ERROR_RATE% exceeds threshold. Rolling back."
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=$PREVIOUS_REVISION=100
exit 1
fi
echo "Minute $i: Error rate $ERROR_RATE% — OK"
done
Rollback de migraciones de base de datos
Esta es la parte más difícil. Si tu despliegue incluye cambios de esquema de base de datos, revertir la aplicación sin revertir la base de datos crea un desajuste. La solución es migraciones expand-and-contract:
- Expand: Agrega nuevas columnas/tablas sin eliminar las antiguas. Haz las nuevas columnas nullable o con valores por defecto.
- Deploy: El nuevo código escribe tanto en las columnas antiguas como en las nuevas. Lee de las nuevas con fallback a las antiguas.
- Migrar datos: Rellena las nuevas columnas con datos de las antiguas.
- Contract: Una vez verificado, despliega código que solo usa las nuevas columnas. Luego elimina las columnas antiguas.
Esto hace que cada paso sea independientemente reversible.
Gestión de secrets
Nunca hardcodees secrets. Nunca hagas commit de archivos .env. Así es como manejo secrets en GitHub Actions:
GitHub Secrets
Para la mayoría de los casos, los secrets integrados de GitHub son suficientes. Están encriptados, nunca se exponen en logs y tienen alcance por repositorio u organización.
env:
DATABASE_URL: ${{ secrets.DATABASE_URL }}
API_KEY: ${{ secrets.API_KEY }}
Secrets con alcance por entorno
Diferentes secrets para staging y producción:
deploy-staging:
environment: staging
# ${{ secrets.DATABASE_URL }} resolves to the staging value
deploy-production:
environment: production
# ${{ secrets.DATABASE_URL }} resolves to the production value
Gestores de secrets externos
Para equipos más grandes o requisitos de cumplimiento más estrictos, usa AWS Secrets Manager, Google Secret Manager o HashiCorp Vault. La aplicación obtiene los secrets en tiempo de ejecución en lugar de recibirlos como variables de entorno.
import { SecretManagerServiceClient } from '@google-cloud/secret-manager';
const client = new SecretManagerServiceClient();
async function getSecret(name: string): Promise<string> {
const [version] = await client.accessSecretVersion({
name: `projects/my-project/secrets/${name}/versions/latest`,
});
return version.payload?.data?.toString() || '';
}
Monitoreo de despliegues
Un despliegue no está terminado cuando el código está en producción. Está terminado cuando has confirmado que el código está funcionando.
Notificaciones de despliegue
Envía eventos de despliegue a Slack con contexto relevante:
- name: Notify Slack
if: always()
uses: slackapi/slack-github-action@v2
with:
webhook: ${{ secrets.SLACK_WEBHOOK }}
webhook-type: incoming-webhook
payload: |
{
"text": "${{ job.status == 'success' && 'Deployed' || 'Failed to deploy' }} `${{ github.sha }}` to production",
"blocks": [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*${{ job.status == 'success' && ':white_check_mark: Deployment Successful' || ':x: Deployment Failed' }}*\nCommit: `${{ github.sha }}`\nAuthor: ${{ github.actor }}\nMessage: ${{ github.event.head_commit.message }}"
}
}
]
}
Health checks post-despliegue
Después de cada despliegue a producción, verifica que los endpoints críticos respondan correctamente:
- name: Verify production health
run: |
endpoints=("/" "/api/health" "/api/v1/status")
for endpoint in "${endpoints[@]}"; do
status=$(curl -s -o /dev/null -w "%{http_code}" "https://api.example.com$endpoint")
if [ "$status" != "200" ]; then
echo "FAILED: $endpoint returned $status"
exit 1
fi
echo "OK: $endpoint returned $status"
done
Un ejemplo completo de pipeline
Juntando todo, aquí hay un pipeline condensado pero completo para una aplicación Node.js desplegada en Cloud Run:
name: CI/CD Pipeline
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: ${{ github.event_name == 'pull_request' }}
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx prettier --check "src/**/*.{ts,tsx}"
- run: npx eslint src/ --max-warnings 0
- run: npx tsc --noEmit
test:
needs: validate
runs-on: ubuntu-latest
services:
postgres:
image: postgres:16
env: { POSTGRES_USER: test, POSTGRES_PASSWORD: test, POSTGRES_DB: testdb }
ports: ['5432:5432']
options: --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx vitest run --coverage
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
build-and-push:
needs: test
if: github.event_name == 'push'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: docker/setup-buildx-action@v3
- uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- uses: docker/build-push-action@v6
with:
context: .
push: true
tags: ghcr.io/${{ github.repository }}:${{ github.sha }}
cache-from: type=gha
cache-to: type=gha,mode=max
deploy:
needs: build-and-push
runs-on: ubuntu-latest
environment:
name: ${{ github.ref == 'refs/heads/main' && 'production' || 'staging' }}
steps:
- uses: google-github-actions/auth@v2
with:
credentials_json: ${{ secrets.GCP_SA_KEY }}
- uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-${{ github.ref == 'refs/heads/main' && 'prod' || 'staging' }}
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
El bloque concurrency vale la pena mencionarlo — cancela ejecuciones en progreso para la misma rama en pull requests, así que hacer push de una corrección mientras el CI sigue ejecutándose no pone en cola dos pipelines.
Lo que haría diferente empezando de cero
Si estuviera configurando un pipeline desde cero hoy, comenzaría solo con las etapas de validación y tests — sin automatización de despliegue. Desplegaría manualmente (o con un simple script de deploy) durante las primeras semanas mientras la base de código se estabiliza. Agregaría la automatización del despliegue una vez que el proceso manual se convierta en el cuello de botella, no antes. La optimización prematura de pipelines es tan real como la optimización prematura de código, y depurar un pipeline de despliegue roto a las 2 AM es significativamente peor que ejecutar ./deploy.sh a mano.
Proyectos Relacionados
RestoHub
Los restaurantes dejan de perder el 30% con Uber Eats — obtienen su propio sistema de pedidos, menu, sitio web y programa de fidelizacion en una sola plataforma. Experiencia completa al estilo Uber Eats, pero el restaurante se queda con cada dolar.
TakeCare
Ahora un solo enfermero monitorea 250 pacientes a distancia — reemplazando llamadas telefonicas manuales y visitas domiciliarias en los hospitales mas grandes de Quebec. En funcionamiento en Jewish General, CHUM y Douglas Mental Health Institute.
Danil Ulmashev
Full Stack Developer
Interesado en trabajar juntos?