CI/CD-Pipeline-Setup, das in der Produktion wirklich funktioniert
Praxiserprobte CI/CD-Patterns für echte Projekte — von GitHub Actions Workflows bis zu Deployment-Strategien, die am Freitag nicht die Produktion zerstören.
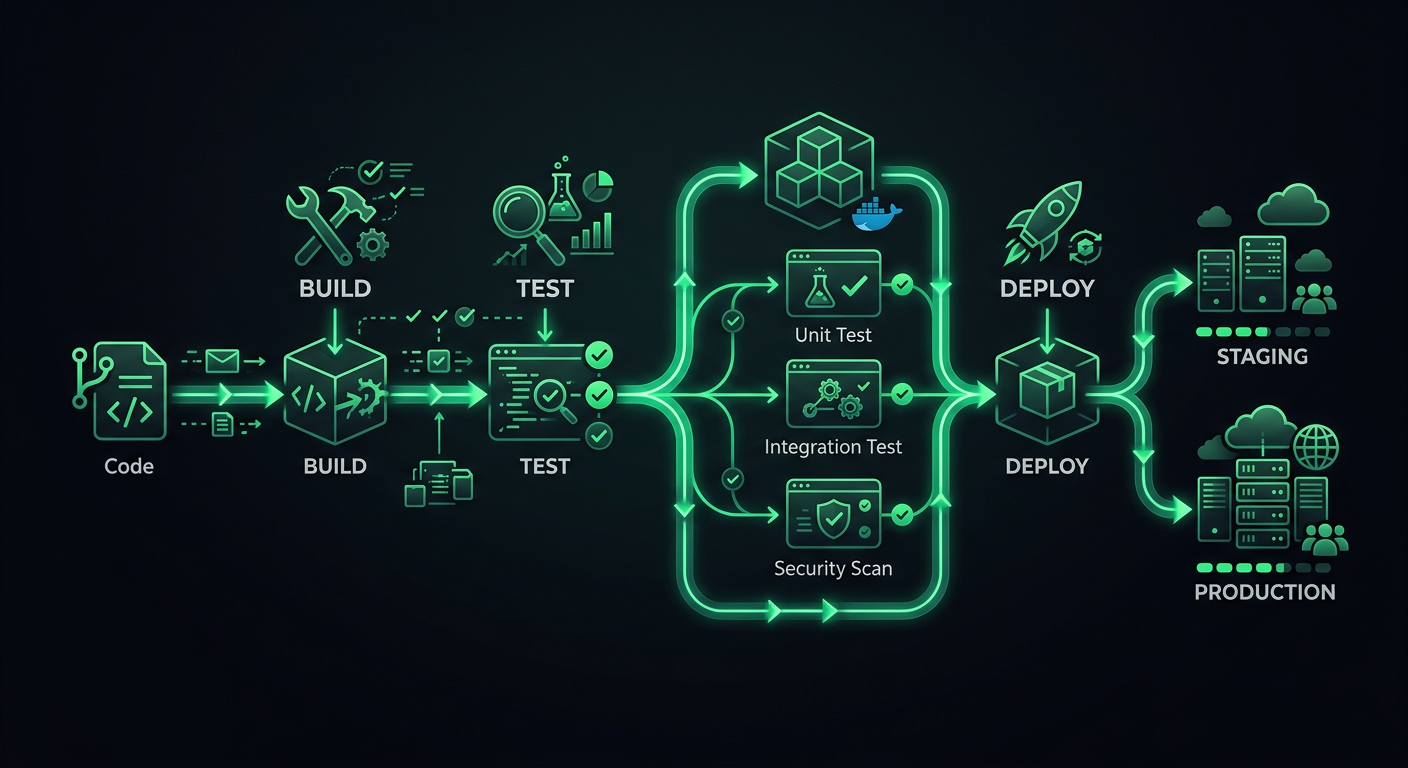
Die erste CI/CD-Pipeline, die ich für ein Produktionsprojekt eingerichtet habe, war ein einzelner GitHub Actions Workflow, der npm test ausführte und dann per SSH auf einen VPS deployte. Es funktionierte, bis es das nicht mehr tat — ein fehlgeschlagenes Deployment hinterließ den Server an einem Freitagabend in einem halb-aktualisierten Zustand, und ich verbrachte das Wochenende damit, Dateien manuell zurückzusetzen. Diese Erfahrung lehrte mich, dass eine Deployment-Pipeline nicht einfach „Tests ausführen, dann deployen" ist. Es ist das gesamte System aus Prüfungen, Gates und Rollback-Mechanismen, das zwischen einem git push und dem neuen Code bei Ihren Nutzern steht.
Dieser Beitrag behandelt die Pipeline-Architektur, die ich über mehrere Produktionsprojekte verfeinert habe, mit konkreten GitHub Actions Beispielen, die Sie anpassen können.
Pipeline-Architektur
Eine Produktions-Pipeline hat unterschiedliche Stufen, und jede Stufe hat einen bestimmten Zweck. Stufen zu überspringen spart jetzt Minuten und kostet später Stunden.
Die Stufen
Code Push
│
├─→ Stufe 1: Validierung (Lint, Format, Type-Check)
│
├─→ Stufe 2: Tests (Unit, Integration)
│
├─→ Stufe 3: Build (Kompilieren, Bundlen, Containerisieren)
│
├─→ Stufe 4: Deploy auf Staging
│
├─→ Stufe 5: Smoke Tests / E2E auf Staging
│
└─→ Stufe 6: Deploy auf Produktion
Jede Stufe fungiert als Gate. Wenn die Validierung fehlschlägt, laufen die Tests nie. Wenn die Tests fehlschlagen, startet der Build nie. Das spart Rechenzeit und bietet schnelles Feedback — Entwickler wissen innerhalb von 30 Sekunden, ob sie vergessen haben, den Linter auszuführen, statt 8 Minuten auf das Scheitern der Test-Suite zu warten.
Trigger-Strategie
Nicht jeder Push braucht die volle Pipeline. Hier ist die Trigger-Konfiguration, die ich verwende:
# .github/workflows/ci.yml
name: CI
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
types: [opened, synchronize, reopened]
Pull Requests führen die Stufen 1-3 aus (Validierung, Test, Build). Merges in develop deployen auf Staging. Merges in main deployen auf Produktion. Das hält PR-Feedback schnell und stellt sicher, dass Deployments nur von geschützten Branches erfolgen.
Stufe 1: Validierung
Die Validierung fängt Formatierungsinkonsistenzen und Typfehler ab, bevor Tests laufen. Diese Prüfungen sind schnell (unter 30 Sekunden) und erkennen die häufigsten Probleme.
jobs:
validate:
name: Validate
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Check formatting
run: npx prettier --check "src/**/*.{ts,tsx,js,jsx,json,css}"
- name: Lint
run: npx eslint src/ --max-warnings 0
- name: Type check
run: npx tsc --noEmit
Die --max-warnings 0-Regel
ESLint unterscheidet zwischen Fehlern (die den Prozess beenden) und Warnungen (die das nicht tun). Ohne --max-warnings 0 sammeln Teams Hunderte von Warnungen an, die jeder ignoriert. Warnungen in CI als Fehler zu behandeln zwingt das Team, sie entweder zu beheben oder die Regel explizit zu deaktivieren. Kein Mittelweg.
Formatierung als CI-Prüfung, nicht nur als Vorschlag
Prettier in CI auszuführen (mit --check, nicht --write) stellt konsistente Formatierung sicher, ohne sich darauf zu verlassen, dass jeder Entwickler die richtige Editor-Erweiterung hat. Wenn die Formatierung in CI fehlschlägt, führt der Entwickler lokal npx prettier --write . aus und committet den Fix. Das ist nicht verhandelbar — Formatierungsdebatten enden, wenn ein Tool die Entscheidungen trifft.
Stufe 2: Tests
Tests sind das Rückgrat der Pipeline. Ich teile Tests in parallele Jobs nach Typ auf für schnelleres Feedback.
unit-tests:
name: Unit Tests
runs-on: ubuntu-latest
needs: validate
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run unit tests
run: npx vitest run --coverage --reporter=verbose
- name: Upload coverage report
if: always()
uses: actions/upload-artifact@v4
with:
name: coverage-report
path: coverage/
integration-tests:
name: Integration Tests
runs-on: ubuntu-latest
needs: validate
services:
postgres:
image: postgres:16
env:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
POSTGRES_DB: testdb
ports:
- 5432:5432
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
redis:
image: redis:7
ports:
- 6379:6379
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run database migrations
run: npx prisma migrate deploy
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
- name: Run integration tests
run: npx vitest run --config vitest.integration.config.ts
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
REDIS_URL: redis://localhost:6379
Service-Container für Integrationstests
GitHub Actions Service-Container werden zu wenig genutzt. Anstatt Ihre Datenbank in Integrationstests zu mocken (was den Mock testet, nicht Ihren Code), starten Sie eine echte PostgreSQL-Instanz. Der services-Block verwaltet den Lebenszyklus — der Container startet vor Ihren Tests und stoppt danach.
Das fügt dem Job etwa 15-20 Sekunden für den Container-Start hinzu, aber das Vertrauen, das Sie durch Tests gegen eine echte Datenbank gewinnen, ist es wert.
Parallele Testausführung
Unit-Tests und Integrationstests laufen parallel (beide needs: validate, nicht needs: unit-tests). Das reduziert die gesamte Pipeline-Zeit. Wenn Ihre Unit-Tests 2 Minuten und Integrationstests 4 Minuten dauern, bedeutet parallele Ausführung 4 Minuten Wartezeit statt 6.
Stufe 3: Build
Die Build-Stufe validiert, dass das Projekt kompiliert und deploybare Artefakte erzeugt.
build:
name: Build
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Build application
run: npm run build
env:
NODE_ENV: production
- name: Upload build artifacts
uses: actions/upload-artifact@v4
with:
name: build-output
path: dist/
retention-days: 7
Build-Caching
Für Docker-basierte Deployments beschleunigt Layer-Caching Builds dramatisch:
build-docker:
name: Build Docker Image
runs-on: ubuntu-latest
needs: [unit-tests, integration-tests]
steps:
- uses: actions/checkout@v4
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to Container Registry
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v6
with:
context: .
push: ${{ github.event_name != 'pull_request' }}
tags: |
ghcr.io/${{ github.repository }}:${{ github.sha }}
ghcr.io/${{ github.repository }}:latest
cache-from: type=gha
cache-to: type=gha,mode=max
Das cache-from: type=gha nutzt den GitHub Actions Cache, um Docker-Layer zwischen Durchläufen zu speichern. Für eine typische Node.js-Anwendung reduziert dies die Build-Zeit von 3-4 Minuten auf 30-60 Sekunden bei reinen Dependency-Änderungen.
Dockerfile Best Practices für CI
Die Dockerfile-Struktur beeinflusst direkt die Build-Cache-Effizienz. Ordnen Sie Layer von am seltensten geändert zu am häufigsten geändert:
FROM node:20-alpine AS base
# System dependencies (rarely changes)
RUN apk add --no-cache libc6-compat
# Package manifests (changes when dependencies change)
WORKDIR /app
COPY package.json package-lock.json ./
# Install dependencies (cached unless manifests change)
FROM base AS deps
RUN npm ci --production
FROM base AS build
RUN npm ci
COPY . .
RUN npm run build
# Production image
FROM node:20-alpine AS runner
WORKDIR /app
ENV NODE_ENV=production
COPY --from=deps /app/node_modules ./node_modules
COPY --from=build /app/dist ./dist
COPY --from=build /app/package.json ./
EXPOSE 3000
CMD ["node", "dist/server.js"]
Multi-Stage-Builds halten das finale Image klein (keine Dev-Dependencies, kein Quellcode), und die Layer-Anordnung stellt sicher, dass npm ci nur läuft, wenn sich package.json oder package-lock.json ändert.
Stufe 4: Deployment auf Staging
Das Staging-Deployment erfolgt automatisch bei Merges in den develop-Branch. Die Staging-Umgebung sollte die Produktion so genau wie möglich widerspiegeln — gleiche Infrastruktur, gleiche Umgebungsvariablen (mit anderen Werten), gleiche Skalierungskonfiguration.
deploy-staging:
name: Deploy to Staging
runs-on: ubuntu-latest
needs: build
if: github.ref == 'refs/heads/develop' && github.event_name == 'push'
environment:
name: staging
url: https://staging.example.com
steps:
- uses: actions/checkout@v4
- name: Download build artifacts
uses: actions/download-artifact@v4
with:
name: build-output
path: dist/
- name: Deploy to Cloud Run (Staging)
uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-staging
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
env_vars: |
NODE_ENV=staging
DATABASE_URL=${{ secrets.STAGING_DATABASE_URL }}
GitHub Environments
Der environment-Key im Workflow aktiviert GitHubs Environment-Schutzregeln. Sie können manuelle Genehmigung verlangen, einschränken, welche Branches deployen können, und umgebungsspezifische Secrets setzen. Für Staging verlange ich typischerweise keine Genehmigung (Auto-Deploy). Für Produktion verlange ich mindestens einen Reviewer.
Stufe 5: Smoke Tests
Nach dem Deployment auf Staging führen Sie einen grundlegenden Satz von Tests gegen die deployte Anwendung aus, um zu verifizieren, dass sie in der realen Umgebung tatsächlich funktioniert.
smoke-tests:
name: Smoke Tests
runs-on: ubuntu-latest
needs: deploy-staging
steps:
- uses: actions/checkout@v4
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 20
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Wait for deployment
run: |
for i in {1..30}; do
status=$(curl -s -o /dev/null -w "%{http_code}" https://staging.example.com/health)
if [ "$status" = "200" ]; then
echo "Service is healthy"
exit 0
fi
echo "Waiting for service... (attempt $i)"
sleep 10
done
echo "Service did not become healthy"
exit 1
- name: Run smoke tests
run: npx playwright test --config=playwright.smoke.config.ts
env:
BASE_URL: https://staging.example.com
Smoke Tests sind keine vollständigen E2E-Tests. Sie verifizieren kritische Pfade: Kann die Startseite laden, kann sich ein Nutzer anmelden, liefert der Haupt-API-Endpunkt Daten. Fünf bis zehn Szenarien, die unter 2 Minuten dauern. Wenn Smoke Tests fehlschlagen, wird das Staging-Deployment zurückgerollt und das Produktions-Deployment findet nicht statt.
Stufe 6: Produktions-Deployment
Das Produktions-Deployment ist der Punkt, an dem die Deployment-Strategie am meisten zählt. Es gibt mehrere Ansätze, jeder mit unterschiedlichen Kompromissen.
Rolling Deployment
Die einfachste Strategie. Neue Instanzen werden hochgefahren, während alte Instanzen abgebaut werden. Zu jedem Zeitpunkt während des Deployments treffen einige Anfragen die alte Version und einige die neue. Das ist der Standard für die meisten Container-Plattformen.
Vorteile: Einfach, keine zusätzlichen Infrastrukturkosten. Nachteile: Zwei Versionen bedienen gleichzeitig Traffic, was Probleme mit Datenbankschema-Änderungen oder API-Vertragsänderungen verursachen kann.
Blue-Green Deployment
Zwei identische Umgebungen (Blue und Green) existieren. Eine bedient Traffic, die andere ist inaktiv. Deployen Sie auf die inaktive Umgebung, verifizieren Sie, dass sie funktioniert, dann wechseln Sie den Router. Wenn etwas schiefgeht, wechseln Sie zurück.
deploy-production:
name: Deploy to Production
runs-on: ubuntu-latest
needs: smoke-tests
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
environment:
name: production
url: https://api.example.com
steps:
- name: Deploy new revision
uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-production
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
flags: '--no-traffic'
- name: Run production health check
run: |
REVISION_URL=$(gcloud run revisions describe my-api-production-${{ github.sha }} \
--region us-central1 --format='value(status.url)')
status=$(curl -s -o /dev/null -w "%{http_code}" "$REVISION_URL/health")
if [ "$status" != "200" ]; then
echo "Health check failed"
exit 1
fi
- name: Migrate traffic
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
Das --no-traffic-Flag deployt die neue Revision, ohne ihr Traffic zu senden. Nach bestandenem Health Check wird der Traffic auf die neue Revision umgeleitet. Wenn der Health Check fehlschlägt, stoppt der Workflow und die alte Revision bedient weiter.
Canary Deployment
Leiten Sie einen kleinen Prozentsatz des Traffics (5-10 %) auf die neue Version, während Sie Fehlerraten, Latenz und wichtige Geschäftsmetriken überwachen. Wenn die Metriken nach einem definierten Zeitraum gut aussehen, erhöhen Sie den Traffic schrittweise. Wenn die Metriken sich verschlechtern, rollen Sie zurück.
- name: Canary - route 10% of traffic
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=my-api-production-${{ github.sha }}=10
- name: Monitor canary (5 minutes)
run: |
sleep 300
# Check error rate for the canary revision
ERROR_RATE=$(curl -s "$MONITORING_API/error-rate?revision=${{ github.sha }}")
if (( $(echo "$ERROR_RATE > 1.0" | bc -l) )); then
echo "Error rate too high: $ERROR_RATE%. Rolling back."
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
exit 1
fi
- name: Promote canary to 100%
run: |
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-latest
Wann Canary einsetzen: Wenn Sie genug Traffic haben, dass 10 % noch statistisch aussagekräftige Fehlerraten generieren. Für einen Service, der 100 Anfragen/Minute bearbeitet, gibt Ihnen 10 % 10 Anfragen/Minute — genug, um erhöhte Fehlerraten innerhalb weniger Minuten zu erkennen. Für einen Service, der 10 Anfragen/Minute bearbeitet, sind Canary-Deployments nicht aussagekräftig.
Rollback-Mechanismen
Jedes Deployment muss einen dokumentierten Rollback-Pfad haben. „Die alte Version erneut deployen" ist eine Rollback-Strategie, aber sie ist langsam. Bessere Optionen:
Sofortiges Rollback via Traffic-Shifting
Wenn Sie mit --no-traffic deployen und Traffic umleiten, ist ein Rollback ein einzelner Befehl:
# Roll back to the previous revision
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=PREVIOUS_REVISION=100
Das wirkt in Sekunden, weil die alte Revision noch läuft.
Automatisiertes Rollback
Fügen Sie einen Post-Deployment-Monitoring-Schritt hinzu, der automatisch zurückrollt, wenn Fehlerraten steigen:
- name: Post-deploy monitor
run: |
for i in {1..10}; do
sleep 60
ERROR_RATE=$(curl -s "$MONITORING_API/error-rate?window=5m")
if (( $(echo "$ERROR_RATE > 2.0" | bc -l) )); then
echo "Error rate $ERROR_RATE% exceeds threshold. Rolling back."
gcloud run services update-traffic my-api-production \
--region us-central1 \
--to-revisions=$PREVIOUS_REVISION=100
exit 1
fi
echo "Minute $i: Error rate $ERROR_RATE% — OK"
done
Datenbank-Migrations-Rollback
Das ist der schwierigste Teil. Wenn Ihr Deployment Datenbankschema-Änderungen enthält, entsteht beim Zurückrollen der Anwendung ohne Zurückrollen der Datenbank ein Mismatch. Die Lösung sind Expand-and-Contract-Migrationen:
- Expand: Neue Spalten/Tabellen hinzufügen, ohne alte zu entfernen. Neue Spalten nullable oder mit Defaults machen.
- Deploy: Neuer Code schreibt in alte und neue Spalten. Liest aus neuen Spalten mit Fallback auf alte.
- Daten migrieren: Neue Spalten aus alten Daten befüllen.
- Contract: Sobald verifiziert, Code deployen, der nur neue Spalten nutzt. Dann alte Spalten entfernen.
Das macht jeden Schritt einzeln reversibel.
Secrets-Management
Niemals Secrets hartcoden. Niemals .env-Dateien committen. So handhabe ich Secrets in GitHub Actions:
GitHub Secrets
Für die meisten Fälle reichen GitHubs eingebaute Secrets aus. Sie sind verschlüsselt, werden nie in Logs exponiert und sind auf Repositories oder Organisationen beschränkt.
env:
DATABASE_URL: ${{ secrets.DATABASE_URL }}
API_KEY: ${{ secrets.API_KEY }}
Umgebungsbezogene Secrets
Verschiedene Secrets für Staging und Produktion:
deploy-staging:
environment: staging
# ${{ secrets.DATABASE_URL }} resolves to the staging value
deploy-production:
environment: production
# ${{ secrets.DATABASE_URL }} resolves to the production value
Externe Secret-Manager
Für größere Teams oder strengere Compliance-Anforderungen verwenden Sie AWS Secrets Manager, Google Secret Manager oder HashiCorp Vault. Die Anwendung ruft Secrets zur Laufzeit ab, anstatt sie als Umgebungsvariablen zu erhalten.
import { SecretManagerServiceClient } from '@google-cloud/secret-manager';
const client = new SecretManagerServiceClient();
async function getSecret(name: string): Promise<string> {
const [version] = await client.accessSecretVersion({
name: `projects/my-project/secrets/${name}/versions/latest`,
});
return version.payload?.data?.toString() || '';
}
Deployment-Monitoring
Ein Deployment ist nicht erledigt, wenn der Code live ist. Es ist erledigt, wenn Sie bestätigt haben, dass der Code funktioniert.
Deployment-Benachrichtigungen
Senden Sie Deployment-Events an Slack mit relevantem Kontext:
- name: Notify Slack
if: always()
uses: slackapi/slack-github-action@v2
with:
webhook: ${{ secrets.SLACK_WEBHOOK }}
webhook-type: incoming-webhook
payload: |
{
"text": "${{ job.status == 'success' && 'Deployed' || 'Failed to deploy' }} `${{ github.sha }}` to production",
"blocks": [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*${{ job.status == 'success' && ':white_check_mark: Deployment Successful' || ':x: Deployment Failed' }}*\nCommit: `${{ github.sha }}`\nAuthor: ${{ github.actor }}\nMessage: ${{ github.event.head_commit.message }}"
}
}
]
}
Post-Deployment Health Checks
Nach jedem Produktions-Deployment verifizieren Sie, dass kritische Endpunkte korrekt antworten:
- name: Verify production health
run: |
endpoints=("/" "/api/health" "/api/v1/status")
for endpoint in "${endpoints[@]}"; do
status=$(curl -s -o /dev/null -w "%{http_code}" "https://api.example.com$endpoint")
if [ "$status" != "200" ]; then
echo "FAILED: $endpoint returned $status"
exit 1
fi
echo "OK: $endpoint returned $status"
done
Ein vollständiges Pipeline-Beispiel
Alles zusammengesetzt, hier eine komprimierte aber vollständige Pipeline für eine Node.js-Anwendung, die auf Cloud Run deployt wird:
name: CI/CD Pipeline
on:
push:
branches: [main, develop]
pull_request:
branches: [main, develop]
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: ${{ github.event_name == 'pull_request' }}
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx prettier --check "src/**/*.{ts,tsx}"
- run: npx eslint src/ --max-warnings 0
- run: npx tsc --noEmit
test:
needs: validate
runs-on: ubuntu-latest
services:
postgres:
image: postgres:16
env: { POSTGRES_USER: test, POSTGRES_PASSWORD: test, POSTGRES_DB: testdb }
ports: ['5432:5432']
options: --health-cmd pg_isready --health-interval 10s --health-timeout 5s --health-retries 5
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with: { node-version: 20, cache: 'npm' }
- run: npm ci
- run: npx vitest run --coverage
env:
DATABASE_URL: postgresql://test:test@localhost:5432/testdb
build-and-push:
needs: test
if: github.event_name == 'push'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: docker/setup-buildx-action@v3
- uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- uses: docker/build-push-action@v6
with:
context: .
push: true
tags: ghcr.io/${{ github.repository }}:${{ github.sha }}
cache-from: type=gha
cache-to: type=gha,mode=max
deploy:
needs: build-and-push
runs-on: ubuntu-latest
environment:
name: ${{ github.ref == 'refs/heads/main' && 'production' || 'staging' }}
steps:
- uses: google-github-actions/auth@v2
with:
credentials_json: ${{ secrets.GCP_SA_KEY }}
- uses: google-github-actions/deploy-cloudrun@v2
with:
service: my-api-${{ github.ref == 'refs/heads/main' && 'prod' || 'staging' }}
region: us-central1
image: ghcr.io/${{ github.repository }}:${{ github.sha }}
Der concurrency-Block ist bemerkenswert — er bricht laufende Durchläufe für denselben Branch bei Pull Requests ab, sodass das Pushen eines Fixes während CI noch läuft nicht zwei Pipelines in die Warteschlange stellt.
Was ich anders machen würde, wenn ich von vorn anfinge
Wenn ich heute eine Pipeline von Grund auf einrichten würde, würde ich nur mit den Validierungs- und Test-Stufen beginnen — keine Deployment-Automatisierung. Die ersten Wochen manuell deployen (oder mit einem einfachen Deploy-Skript), während die Codebase sich stabilisiert. Deployment-Automatisierung erst hinzufügen, wenn der manuelle Prozess zum Engpass wird, nicht vorher. Vorzeitige Pipeline-Optimierung ist genauso real wie vorzeitige Code-Optimierung, und das Debuggen einer kaputten Deployment-Pipeline um 2 Uhr morgens ist erheblich schlimmer als ./deploy.sh von Hand auszuführen.
Verwandte Projekte
RestoHub
Restaurants verlieren keine 30 % mehr an Uber Eats — sie bekommen ihr eigenes Bestell-, Menü-, Website- und Treueprogramm-System auf einer Plattform. Vollwertiges Uber-Eats-Erlebnis, aber das Restaurant behält jeden Cent.
TakeCare
Eine Pflegekraft überwacht jetzt 250 Patienten aus der Ferne — anstelle von manuellen Telefonaten und Hausbesuchen in Quebecs größten Krankenhäusern. Im Einsatz im Jewish General, CHUM und Douglas Mental Health Institute.
Danil Ulmashev
Full Stack Developer
Interesse an einer Zusammenarbeit?